I received a few complaints that #embed was difficult to implement and hard to optimize. And, the people making these claims are not exactly wrong. While std::embed was designed to be very simple and easy, the new #embed directive does the usual C thing: it’s “simple” on its face, but because of how C and C++ work and how the languages gel it has a ton of devils in the details. In this post, I’m going to describe the way I implemented #embed in both GCC and Clang and the style of work I used to support the few companies/vendors I did for an early version of #embed. I’ll use the publicly available version of #embed that I offered to Clang as a tool to display one of the usable techniques to get the guaranteed speedup for the subset of cases that matter (e.g., char/signed char/unsigned char array initialization).
Let’s get started.
Support Level 0: Basic #embed Expansion
Before we talk about the fast version of #embed, we need to discuss what it is specified to be. Consider the following two data files:
single_byte.txt:
a
art.txt:
__ _
.-.' `; `-._ __ _
(_, .-:' `; `-._
,'o"( (_, )
(__,-' ,'o"( )>
( (__,-' )
`-'._.--._( )
||| |||`-'._.--._.-'
||| |||
We posit these are UTF-8 encoded text files, meaning the byte value of a is 97 (hexadecimal 0x61) with a size of 1 for the single_byte.txt, and the art.txt file has multiple values with a size of 275 (including the trailing \n newline). We then deploy these files using #embed, a new directive standardized in C23 and in-progress for standardization for C++26:
const unsigned char arr[] = {
#embed <art.txt>
};
int main () {
return
#embed <single_byte.txt>
;
}
The way #embed works is, conceptually, very simple: the preprocessor (stages 1 through 4 of the 7 stage compilation process of C and C++) expands the directive, according to any embed parameters and the file, and produces an “comma-delimited list of integer constant expressions” (or “integral constant expressions cast to unsigned char” for C++, but they mean the same thing here1). Each value goes from 0 to 2552. So, for the files above and the given program, that would look like this:
const unsigned char arr[] = {
0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x5f,
0x5f, 0x20, 0x20, 0x5f, 0x0a, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20,
0x2e, 0x2d, 0x2e, 0x27, 0x20, 0x20, 0x60, 0x3b, 0x20, 0x60, 0x2d, 0x2e,
0x5f, 0x20, 0x20, 0x5f, 0x5f, 0x20, 0x20, 0x5f, 0x0a, 0x20, 0x20, 0x20,
0x20, 0x20, 0x20, 0x28, 0x5f, 0x2c, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20,
0x20, 0x20, 0x20, 0x2e, 0x2d, 0x3a, 0x27, 0x20, 0x20, 0x60, 0x3b, 0x20,
0x60, 0x2d, 0x2e, 0x5f, 0x0a, 0x20, 0x20, 0x20, 0x20, 0x2c, 0x27, 0x6f,
0x22, 0x28, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x28, 0x5f,
0x2c, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20,
0x29, 0x0a, 0x20, 0x20, 0x20, 0x28, 0x5f, 0x5f, 0x2c, 0x2d, 0x27, 0x20,
0x20, 0x20, 0x20, 0x20, 0x20, 0x2c, 0x27, 0x6f, 0x22, 0x28, 0x20, 0x20,
0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x29, 0x3e,
0x0a, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x28, 0x20, 0x20, 0x20, 0x20,
0x20, 0x20, 0x20, 0x28, 0x5f, 0x5f, 0x2c, 0x2d, 0x27, 0x20, 0x20, 0x20,
0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x29, 0x0a, 0x20,
0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x60, 0x2d, 0x27, 0x2e, 0x5f, 0x2e,
0x2d, 0x2d, 0x2e, 0x5f, 0x28, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20,
0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x29, 0x0a, 0x20, 0x20, 0x20, 0x20,
0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x7c, 0x7c, 0x7c, 0x20, 0x20, 0x7c,
0x7c, 0x7c, 0x60, 0x2d, 0x27, 0x2e, 0x5f, 0x2e, 0x2d, 0x2d, 0x2e, 0x5f,
0x2e, 0x2d, 0x27, 0x0a, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20,
0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20,
0x20, 0x7c, 0x7c, 0x7c, 0x20, 0x20, 0x7c, 0x7c, 0x7c, 0x0a
};
int main () {
return
0x61
;
}
Simple enough. The problem with this — which is the problem with depending on program outputs from e.g. xxd -i or random python scripts you wrote because xxd is packaged only VIA vim for some inexplicable reason — is that it is slow. Horrifically slow, in fact. Taking a computer with the following specification:
OS Name: Microsoft Windows 10 Pro
Version: 10.0.19045 Build 19045
System Type: x64-based PC
Processor: AMD Ryzen 9 5950X 16-Core Processor, 3401 MHz, 16 Core(s), 32 Logical Processor(s)
Installed Physical Memory (RAM): 32.0 GB
Total Physical Memory: 31.9 GB
Total Virtual Memory: 36.7 GB
and dropping in a simple 40 MB file potato.bin filled with random data processed through xxd -i takes over 70 seconds to process. And, the worst part is, no matter how much we try to optimize a C++ frontend to parse things faster, the numbers do not get any better! So, we know expanding to a list of integer constants is very bad for build speed: why, then, is #embed specified in this manner? The reality on-the-ground is that C compilers are very weak creatures. Compared to the central 4/5 C++ compilers that exist in the world, there are easily over 100 different C compilers of varying flavors, powers, and implementation effort. At the end of the day, we had to write a specification that allowed the world’s worst compiler to continue being the world’s worst compiler (presumably, because their implementers are making a tradeoff for some other aspect of C they like more).
Therefore, at support level 0, just “expanding to a list of integers” (or a single integer if there is only one byte in the file) is the core behavior. This behavior is not entirely useless, however, and it will notably be used for some of the more interesting cases we will start outlining as we keep on implementing more and more specialized behavior to increase speed.
The first step is, obviously, adding flags to ensure that the compiler frontend knows where to find data. Do NOT use #include paths for this specified through -I: this is a surefire way to make life for users terrifically annoying and difficult and pull in inclusion of headers or data nobody ever wanted. Use a separate flag that provides directories for this. The implementation I made for Clang used -embed-dir WHATEVER and -embed-dir=WHATEVER. Given my data is in a directory called ./media, the invocation would look like: clang -embed-dir=./media/ -o main.exe main.c. All of the search directories are accumulated in order; additionally, the current directory of the file we are working with (e.g., main.c) is used for lookup when #embed "whatever.h" (with quotes) is used.
Now that we can find the files, the way this works in Clang is simple. We create a pseudo-file inside of the compiler, give it a fancy name, and then quite literally just dump the integer literal tokens into it. Stepping back, this:
const unsigned char arr[] = {
#embed <art.txt>
};
int main () {
return
#embed <single_byte.txt>
;
}
Is more faithfully represented by a multi-file split:
////////////////////////////////////////////////
// Enter `main.xxd.cpp`
////////////////////////////////////////////////
const unsigned char arr[] = {
////////////////////////////////////////////////
// Enter `art.txt`-generated
// file internally named `<built-in:embed:1>`
////////////////////////////////////////////////
0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x5f,
0x5f, 0x20, 0x20, 0x5f, 0x0a, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20,
0x2e, 0x2d, 0x2e, 0x27, 0x20, 0x20, 0x60, 0x3b, 0x20, 0x60, 0x2d, 0x2e,
0x5f, 0x20, 0x20, 0x5f, 0x5f, 0x20, 0x20, 0x5f, 0x0a, 0x20, 0x20, 0x20,
0x20, 0x20, 0x20, 0x28, 0x5f, 0x2c, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20,
0x20, 0x20, 0x20, 0x2e, 0x2d, 0x3a, 0x27, 0x20, 0x20, 0x60, 0x3b, 0x20,
0x60, 0x2d, 0x2e, 0x5f, 0x0a, 0x20, 0x20, 0x20, 0x20, 0x2c, 0x27, 0x6f,
0x22, 0x28, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x28, 0x5f,
0x2c, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20,
0x29, 0x0a, 0x20, 0x20, 0x20, 0x28, 0x5f, 0x5f, 0x2c, 0x2d, 0x27, 0x20,
0x20, 0x20, 0x20, 0x20, 0x20, 0x2c, 0x27, 0x6f, 0x22, 0x28, 0x20, 0x20,
0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x29, 0x3e,
0x0a, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x28, 0x20, 0x20, 0x20, 0x20,
0x20, 0x20, 0x20, 0x28, 0x5f, 0x5f, 0x2c, 0x2d, 0x27, 0x20, 0x20, 0x20,
0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x29, 0x0a, 0x20,
0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x60, 0x2d, 0x27, 0x2e, 0x5f, 0x2e,
0x2d, 0x2d, 0x2e, 0x5f, 0x28, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20,
0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x29, 0x0a, 0x20, 0x20, 0x20, 0x20,
0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x7c, 0x7c, 0x7c, 0x20, 0x20, 0x7c,
0x7c, 0x7c, 0x60, 0x2d, 0x27, 0x2e, 0x5f, 0x2e, 0x2d, 0x2d, 0x2e, 0x5f,
0x2e, 0x2d, 0x27, 0x0a, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20,
0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20, 0x20,
0x20, 0x7c, 0x7c, 0x7c, 0x20, 0x20, 0x7c, 0x7c, 0x7c, 0x0a
////////////////////////////////////////////////
// Return to `main.xxd.cpp`
////////////////////////////////////////////////
};
int main () {
return
////////////////////////////////////////////////
// Enter `single_byte.txt`-generated
// file internally named `<built-in:embed:2>`
////////////////////////////////////////////////
0x61
////////////////////////////////////////////////
// Return to `main.xxd.cpp`
////////////////////////////////////////////////
;
}
Internally, there is just a memory buffer called <built-in:embed:1> (where 1 just represents it’s the first file being inserted, 2 would be for the second, and so on and so forth). It is presented as a “file”, and we just “enter” that memory buffer as a “file” and parse it like normal. Very simple stuff, it behaves exactly like #include. As a compiler developer, you also need to make sure you update your support for /showIncludes file dependency generation (MSVC) or -MMD Makefile dependency generation (GCC, Clang, or literally most other compilers). This allows #embed to work pretty much out-of-the-box with your makefile generators and other types of dependency-parsing tools that exist out in the wild, without requiring any updates on the build system side.
A Clang-Specific Explosion
Another Clang-specific part of this that’s very awkward is that you need to generate an actual in-memory source file with this data in it, rather than just directly creating a token stream and pushing that into the compiler’s frontend to handle. The reason here is much less language-design oriented and more compiler-architecture oriented. An earlier version of this code simply generated a sequence of tokens and jammed it back into the parser to deal with. This suddenly caused an inadvertent, potentially infinite number of out-of-bounds reads the part of Clang responsible for dumping token representations back to represent a fully preprocessed file.
The problem was that, somewhat hilariously, rather than Clang hardcoding the write out of things such as comma tokens by using a "," in the compiler’s code to be dumped into the output stream for the preprocessed file, it would simply assume there was a comma in the (original or generated) source code that represented the comma token. That caused the Clang “write preprocessed file” action to go look up a source location for a magic comma token that was being generated but had no backing source data in its SourceManager, and whose source location was just pointing at where the #embed had been. The result was effectively performing random reads of unknown data and piping that straight into the output stream.
It was a fun bug to track down:
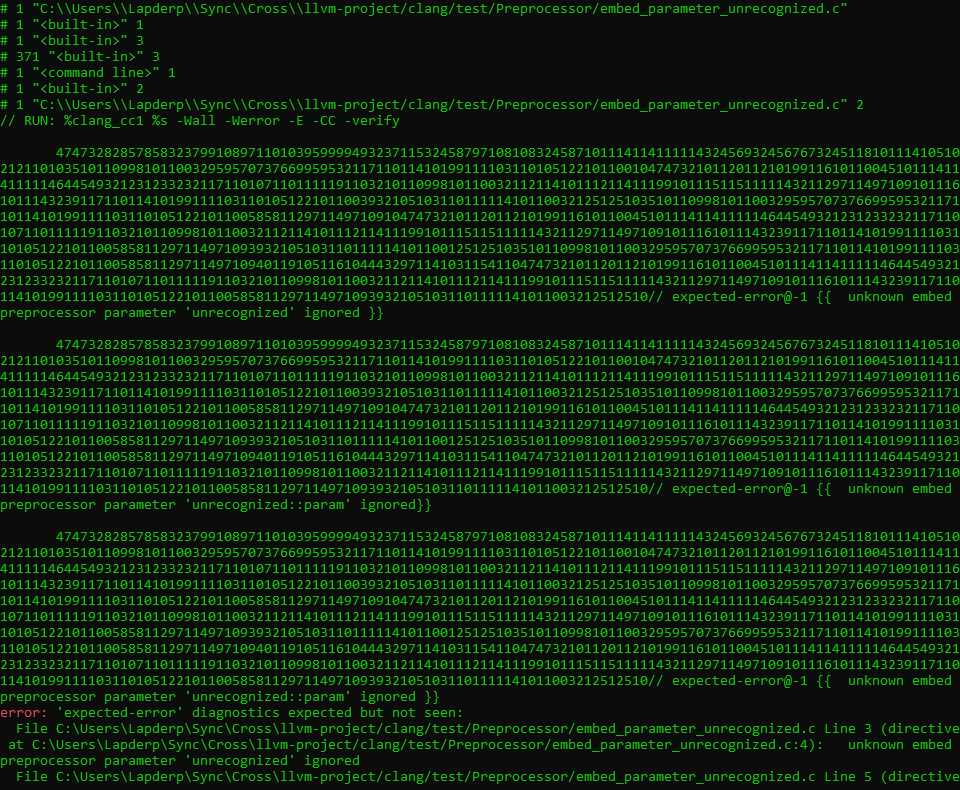
Compiler-specific shenanigans aside…
If you could get away with generating tokens directly rather than source code, that would save you a bit of time performing what most compilers call “tokenization” of source code. But, because I did not feel like dealing with Clang’s source location-based assumptions, I simply generated a source file and had clang process that instead. This results in a fraction of lost time (not too significant, really, but still some work always takes longer than simply not doing the work at all). A more optimized version of this would sidestep these problems deftly and avoid having to re-tokenize raw generated source code back into a sequence of {integer literal} {comma} {integer literal} … tokens.
Nevertheless, solving this issue meant that we could dump out a fully preprocessed file when given the -E option. This meant that specific C and C++ tools that just preprocessed source files and did not retain include flag or embed directory information could reliably parse/process these all-bits-included files that just had the integer list expansion baked right in. This served as the baseline support for #embed. There was just one more thing to do to round out Level 0 support…
Support Level 0, Part II: Preprocessor Parameters
Preprocessor parameters are a newer way to pass additional information to preprocessor directives in C23. They are a whitespace-delimited sequence of foo, bar(potentially-empty-balanced-token-sequence) vendor::baz, or vendor::quux(potentially-empty-balanced-token-sequence) arguments that can be given to a preprocessor directive. They only utilized for the #embed directive at the moment, but as compiler implementers find their bravery to actually start implementing extensions again instead of just constantly poking the Standards Committee to act first, it may start showing up in other places as a means to perform fun tasks.
Fun ideas aside, there’s 4 different preprocessor parameters that are mandated by the C standard for #embed: limit, prefix, suffix, and if_empty.
limit( constant-expression )takes an integer constant expression and lets a file be up to (but no bigger than) the provided limit. This is useful for#embed <infinity_file> limit(value), like#embed </dev/urandom> limit(64).prefix(balanced-token-sequence)/suffix(balanced-token-sequence)both take a sequence of tokens and apply it to the beginning or end of any generated integer token sequence, respectively. If there is no data in the file (or if it is set tolimit(0), which will trigger the file to be considered empty), then this parameter has no effect.if_empty(balanced-token-sequence)takes the sequence of tokens and expands the directive to those tokens, if there is no data in the file (or if it is set tolimit(0)).
Implementing these are not hard: all one has to do is drop the token/text sequence out where expected. So when one encounters the #embed directive and parses the token sequence for prefix or suffix, all they need to do is search for the file. If it’s empty, then they ignore either of the tokens; otherwise, it gets placed before or after the embed directive’s contents. Conversely, if if_empty is present, and the file is empty, then the token sequence appears where the integer sequence would have.
limit(…) is just doing min(limit-expression, size-of-file); if the file size is larger than the limit, than the limit should be chosen. Otherwise, the file size should be chosen. limit(…) specifically refers to the number of integer literals that will be created in the sequence list, and not necessarily the number of bytes. They hold as a 1:1 correlation on most implementations (e.g., CHAR_BIT == size-of-filesystem-byte), but care needs to be taken on the World’s Weirdest Implementations™ (e.g., CHAR_BIT == 9 and fs-byte == 8, or similar foolish shenanigans). The actual wording in the specification for C and C++ has protections against this, but very literally talking about the bit size of the file (or the provided limit-expr ✖ bit width), the bit width of each integer literal, and how the second must cleanly divide into the first. A diagnostic is required if it does not cleanly divide. The full available range can then be defined in interval notation as
\([0, min(limit, file size))\).
There is one other parameter that is part of the Clang implementation that was asked for frequently when I was standardizing #embed. Unfortunately, I am not superhuman and did not have enough time to roll it out into the standard. Part of standardization is, of course, Standardizing Existing Practice, and so as part of the next level of support, adding a few vendor-specific parameters will help bolster adding them to the next C standard.
Support Level 1: clang::offset
This will obviously have to be called gnu::offset for GCC, and then everybody will copy from there. But, the goal is effectively to create and offset( constant-expression ) preprocessor parameter. This does exactly what you’d expect: it would drop up to constant-expression elements from the beginning the read data. This also has the chance to turn the data empty as well, if the offset is greater than the data (after the limit is applied). So, for example:
#embed <single_byte.txt> limit(0) /* empty */
#embed <single_byte.txt> offset(1) /* empty */
#embed </dev/urandom> offset(1) limit(1) /* empty */
#embed </dev/urandom> offset(458946493) limit(1) /* empty */
Notably, the last one is not a constraint violation: it simply just does the min(offset-expression, size-of-file). The full available range can then be defined with interval notation as
\([min(offset, limit, file size), min(limit, file size))\).
There are also many more advanced parameters that can be provided, such as a parameter for width( constant-expression ). This would define the number of bits that would be used for each element to generate the integer literal, which could be useful for initializing larger integral types or custom types when the data is type-punned. But, with that done, I could now move on to speeding the whole thing up! Retaining the support for various constructs above is nuanced, as we will see as we start talking about the next level: built-in speed support.
Support Level 2: Speedy Builtins
So, we implemented a basic preprocessor directive and dumped the contents to a file. It:
- is slow for large files even though we’re generating the data directly in the preprocessor;
- has tooling support (e.g.
icecc/distcc) through “data is directly inside the generated preprocessed file”; - allows us to use it in places where only a single expressions (integer literal) is expected, such as
returnfromint main(); - and, works to initialize an array of
unsigned chartype (or any other type that accepts a list of comma-delimited integer literals).
We need to retain all of these properties, while speeding up the invocation significantly. For this, we implement a compiler-specific built-in. We will call this built-in __builtin_pp_embed. It will take 3 arguments:
- the expected type of each element (for now, always
unsigned char); - the filename as a string literal;
- and, the data encoded as a base64 string literal.
There are more advanced3 versions of this built-in that I have implemented in other versions of this code, but I am not talking about such implementations here. Of course, I am glossing over the most interesting facet of this list: that last bullet point about “base64 string literal”. Some may read that and go ❓❓, and it would not be a bad reaction honestly! It does sound very silly, but it is actually an important facet of the new built-in.
Surviving the -E Tools
One of the requirements for this functionality is that it survives existing tooling. This includes icecc or distcc that employs -E upon the code to generate a single file before throwing it up to a server to build that single preprocessed source file. If you want a “fast” built-in that respects this, then that necessarily means that every time a file is processed with -E — every time data is pulled into a single source file — all of the data must be present. This means that you cannot just put an (absolute) file path into the built-in; icecc and distcc do not replicate the source file tree in any way, shape, or form. Most other tools also do not include full source tree information work this way, nor do any those “send us a single preprocessed file” bug reporting tools for C and C++ toolchains expect your whole working include (and now, embed) directory structure.
Thusly, when you “finish” preprocessing, you need to contain all of the data in a friendly-to-tools manner. Friendly in this case includes being friendly to tools that break source code down into logical source code lines and then use regex to find #include or #embed directives. So, when processing this main.cpp file:
const unsigned char arr[] = {
#embed <art.txt>
};
int main () {
return
#embed <single_byte.txt>
;
}
things end up looking like this when you generate the built-in based code after preprocessing (with large comment block annotations, similar to above code examples):
////////////////////////////////////////////////
// Enter `main.cpp`
////////////////////////////////////////////////
const unsigned char arr[] = {
////////////////////////////////////////////////
// Enter `art.txt`-generated
// file internally named `<built-in:embed:1>`
////////////////////////////////////////////////
__builtin_pp_embed(unsigned char, "/home/derp/pp_embed/examples/media/art.txt",
"ICAgICAgICAgICBfXyAgXwogICAgICAgLi0uJyAgYDsgYC0uXyAgX18g"
"IF8KICAgICAgKF8sICAgICAgICAgLi06JyAgYDsgYC0uXwogICAgLCdv"
"IiggICAgICAgIChfLCAgICAgICAgICAgKQogICAoX18sLScgICAgICAsJ"
"28iKCAgICAgICAgICAgICk+CiAgICAgICggICAgICAgKF9fLC0nICAgIC"
"AgICAgICAgKQogICAgICAgYC0nLl8uLS0uXyggICAgICAgICAgICAgKQo"
"gICAgICAgICAgfHx8ICB8fHxgLScuXy4tLS5fLi0nCiAgICAgICAgICAg"
"ICAgICAgICAgIHx8fCAgfHx8Cg==");
////////////////////////////////////////////////
// Return to `main.cpp`
////////////////////////////////////////////////
};
int main () {
return
////////////////////////////////////////////////
// Enter `single_byte.txt`-generated
// file internally named `<built-in:embed:1>`
////////////////////////////////////////////////
__builtin_pp_embed(unsigned char, "/home/derp/pp_embed/examples/media/single_byte.txt", "YQ==");
////////////////////////////////////////////////
// Return to `main.cpp`
////////////////////////////////////////////////
;
}
Notice how this source file only contains constructs that are:
- blindly ASCII parse-ready;
- do not require access to the original source files anymore;
- and, understandable as normal C or C++ source code.
This means that icecc/distcc-style tools would not trip up a re-run of the compiler on the single unified source file. Base64 encoding the data in the second string literal argument is important, because data from a file could look like either valid C++ source when it is meant to be data or could contain bytes in the data that would absolutely destroy traditional/typical C and C++ tooling (like actual embedded nulls).
A Poorly Conceived Idea
A few C++ implementers had a poorly thought-through idea for how to handle this during -E processing. Particularly, their idea was to inject a special, compiler-specific _Pragma rather than something like __builtin_pp_embed; it would indicate the number of bytes of the #embed‘d file before dumping the data raw into the source file. As you can imagine, doing the _Pragma would mean the fully-preprocessed version of this file:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(void) {
char src[] = {
#embed __FILE__
}, *argv[] = { "./out", NULL };
FILE *fd = fopen("src.c", "w+");
fwrite(src, sizeof(src), 1, fd);
fclose(fd);
system("${CC} src.c -o out");
return execv(argv[0], argv);
}
Would trip most tools up. Tools would not understand a generated compiler-specific _Pragma/#pragma that would contain C++ source code, such as:
/* stdio.h expansion here */
/* stdlib.h expansion here */
/* unistd.h expansion here */
int main(void) {
char src[] = {
///////////////
// start pragma
#pragma embed 286 #include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(void) {
char src[] = {
#embed __FILE__
}, *argv[] = { "./out", NULL };
FILE *fd = fopen("src.c", "w+");
fwrite(src, sizeof(src), 1, fd);
fclose(fd);
system("${CC} src.c -o out");
return execv(argv[0], argv);
}
///////////////
// end pragma
}, *argv[] = { "./out", NULL };
FILE *fd = fopen("src.c", "w+");
fwrite(src, sizeof(src), 1, fd);
fclose(fd);
system("${CC} src.c -o out");
return execv(argv[0], argv);
}
This is, of course, a travesty of new lines and other directives nested in on itself. This absolutely destroys and breaks tooling built on top of -E preprocessed source files. Therefore, the data must be turned into a form that is palpably understandable by something that can handle “regex for function calls” or “regex after logical line processing for preprocessor directives”. Anything that interferes with that idea breaks too much tooling to be (widely) viable, though it may be suitable for internal-only processing. However, if someone has a compiler with a fused preprocessor, C or C++ language frontend, and backend, they could skip this hullabaloo about _Pragmas or built-ins or what-have-you and just blast the memory into the optimal place in the compiler on the first go-around.
All in all, not a worthwhile long-term implementation strategy and one I almost lost a bunch of time trying to make happen; here’s to you not having to make the same mistake as I did.
Nevertheless,
Adding support for this is actually more complicated than imagined. For example, because this is a preprocessor directive, melting things down into a built-in can produce many surprising consequences for where it appears. It’s not just return statements or function invocations; it can appear in arguments, in template parameters, in places where nothing is expected, and so much more:
#embed <media/empty>
;
void f (unsigned char x) { (void)x;}
void g () {}
void h (unsigned char x, int y) {(void)x; (void)y;}
int i () {
return
#embed <single_byte.txt>
;
}
_Static_assert(
#embed <single_byte.txt> suffix(,)
""
);
_Static_assert(
#embed <single_byte.txt>
, ""
);
_Static_assert(sizeof(
#embed <single_byte.txt>
) ==
sizeof(unsigned char)
, ""
);
_Static_assert(sizeof
#embed <single_byte.txt>
, ""
);
_Static_assert(sizeof(
#embed <jk.txt>
) ==
sizeof(unsigned char)
, ""
);
#ifdef __cplusplus
template <int First, int Second>
void j() {
static_assert(First == 'j', "");
static_assert(Second == 'k', "");
}
#endif
void do_stuff() {
f(
#embed <single_byte.txt>
);
g(
#embed <media/empty>
);
h(
#embed <jk.txt>
);
int r = i();
(void)r;
#ifdef __cplusplus
j<
#embed <jk.txt>
>(
#embed <media/empty>
);
#endif
}
This is what cost the majority of the implementation time when working on the built-in. Because the built-in is generated by the preprocessor but parsed by the frontend, handling this was the largest portion of what made it difficult. There’s a few things we did to make all of this work out rather simply, at least in Clang. Different compilers have different architectures, but many of these ideas can be applied universally.
0. Implement __builtin_pp_embed as a Keyword
Trying to parse __builtin_pp_embed as a “built-in function call” versus just grafting support directly into the parser with __builtin_pp_embed explicitly as a keyword is sufficiently more nightmarish. It opts into a lot of mechanisms and code around function calls that assume a single return (not the case for empty embeds or embeds that produce multiple integer literals). It absolutely requires manual tweaking if you want to do things like read a type name as an argument without having your typical function-body parser explode. There are also rules in both C and C++ that automatically decay arrays to pointers when put in normal function calls, making it difficult to retrieve information when you get to the “Semantic Analysis” part of working with code.
Instead, parsing __builtin_pp_embed as a keyword and then simply expecting the parentheses, type name, file name string literal, and string literal arguments results in far less code and far less post-hoc adjustments. It’s also marginally faster than reverse-engineering the proper data during Semantic Analysis and Constant Expression parsing. Internally, this produces a distinct PPEmbedExpr that contains the base64-decoded data as a StringLiteral (Clang) or a distinct VECTOR_CST-style tree node with a string node stored as part of the VECTOR_CST’s data and pattern (GCC). Most compilers have special __builtin_* markers that are treated as private keywords, even TCC. This implementation technique allows you to get right into the special internal format necessary for later processing and speed recognition.
1. Stringent Speed Requirements
In your compiler architecture, you want to eliminate any node or leaf object that represents the built-in as soon as is technologically possible. Specifically for Clang, this is possible by recognizing a sequence of conditions:
- if the built-in is being used to initialize an array of character type (e.g.
charorunsigned charor evensigned char); - and if there is only ONE initializer in the list of initializers for an object that is the built-in;
then, the built-in node or tree element just gets replaced with a magic string literal that was generated from the decoded base64 data. The realization here comes from noting that string literals are, quite literally, the fastest array initializers in almost every C and C++ compiler today. String literals and their initializers are also often rarely copied, making them supremely ideal for the goal of initializing these arrays. This also prevents us from having to give a single damn about further downstream portions of either Clang or GCC’s compiler architecture: just substitute in a single string literal and let the usual “array initialization from a string literal” take hold.
This seemed like a hack, because it meant I did not have to really touch much if any-at-all semantic analysis of Clang’s compiler (earlier versions of my patch got completely lost on the SemaExpr sauce and the constant expression parser trying to gain bigger and bigger speedups) nor did I have to so much as look at the Code Gen. But, it actually paid off enormously, in both implementation speed, implementation correctness, and end result speed. I encourage almost every single compiler to follow the above 2 guidelines; if they cannot form a single initializer with all of the provided initializers so that it can simply be folded down into a typical array initialization of one of the character arrays, then go to Step #2.
2. Aggressively Expand Everywhere Else
If the two conditions above aren’t met and the initializer data cannot be massaged into the moral, spiritual, and factual equivalent of a string literal initialization, expand the directive. This is where things become really difficult, because not everything is allowed to expand in-place. For example, the return __builtin_pp_embed(…); statement cannot handle having 2 integers present. It can work with 1 integer, or with 0 (for a void function that does return ;). This requires manual diagnose when handling a return expression, but has to be done as early as possible in either the parser, or the semantic analyzer. This is where implementation difficulty fully ramps up, and is where I spent the least amount of time for the patch. A lot of things work correctly in the basic case, but extended and honestly completely asinine usages of #embed can and do break the compiler.
Because the compiler was not built to accept a comma-delimited list of integers anywhere and everywhere, the idea that a single expression — __builtin_pp_embed(…) — could turn into one is a fine way to make every part of the compiler scream. So, instead, I focused my energy on getting things correct for the typical usages and a few odd places, and leaving the rest to, effectively, undefined behavior and fate.
Thankfully, there’s a few key places in Clang where All Function Call Arguments are finalized/massaged, and central locations where All Template Arguments are processed, so the two big cases where this may happen are easy to handle. Initialization also has a Single Coalescing Location, which takes care of all structure and array initialization and makes it easy to get the speedup. It’s all the tiny little stragglers that need to be cleaned up, and that’s where my energy levels hit rock bottom. Having already done a lot of this boilerplate over the last 5 years, implementing it all again for #embed and std::embed over and over and over and over is… draining!
3. Recognize Simple Cases in the Preprocessor
Another way to avoid problems with #embed ruining things in unexpected ways in your compiler is — when doing the transition from #embed to __builtin_pp_embed in the preprocessor — simply not generating the built-in when it would not be useful. So, for example, if you detect that the file is empty (limit is too small or offset is too high or both, or the file is legitimately empty), there is absolutely no reason to produce the built-in at all. Just expand it out to nothing and leave. If there’s an if_empty(…), just pour the text directly into a buffer, make it a new file, and deem that the expansion. Let it parse normally, like any other preprocessor expansion. It avoids a wide class of issues related to “how do I delete this tree node / expression leaf out from itself?!”. The inverse of this, of course, is…
4. Recognize When Something Is Not Built-in-able
If you took the advice in the preceding section, then the only time you’re going to make a built-in is if there is data. So, we know for a fact that any suffix(…) or prefix(…) has to be valid and will be put out by the directive. If there is a suffix(…) or prefix(…) parameter, you can do a quick check to see if it is worth your time to turn it into a built-in. For prefixes, check if there is a comma delimited list of integers that end with a comma. For suffixes, check if it starts with a comma and then becomes a comma delimited list of integers after that. If one or both of these hold true, then you can just immediately slurp that data up into whatever binary data was produced, making sure that each integer constant is within the range \([0, 2^{CHAR\_BIT})\). Then you emit a single __builtin_pp_embed without adding any additional tokens before or after it.
If either is not, then just bail and expand the list of integers as programmed in Support Level 0. This was actually pointed out during the C Meeting by Joseph Myers — a prominent contributor to glibc, GCC’s C code, and several other highly used projects — as something implementations can do to keep code optimized as early as possible and not trip up the conditions above. This was also a primary reason why suffix(…) and prefix(…) were kept as embed parameters, despite being able to program this in multiple different ways. For example, all of these will make a null-terminated string:
const char non_optimized0[] = {
#embed "shaders/super_glitter.glsl"
, 0
};
const char non_optimized1[] = {
#embed "shaders/super_glitter.glsl"
#if __has_embed("shaders/super_glitter.glsl") == __STDC_EMBED_FOUND__
,
#endif
0
};
const char optimized0[] = {
#embed "shaders/super_glitter.glsl" \
suffix(, 0)
};
It is worth noting that non_optimized0 also just completely breaks if shaders/super_glitter.glsl is empty. But, assuming there is data in the file, the first two will not optimize cleanly; the current directive will just vomit it out into a mess. Contrarily, the last one will much more easily be optimized by most implementations. Doing this for both prefix(…) and suffix(…) will become increasingly important as people use it to do things such as provide integer sequences that map to things such as "#version 420 or other common top-level string boilerplate for all sorts of files inside of prefix() or suffix() clauses.
But…
That’s it, in terms of implementation prowess. Ostensibly, Support Level 0 is enough to be a conforming implementation. There are tons of examples in the Clang pull request and other places for this. There are also many more extensions that can be implemented for this functionality. I can only hope that implementers that read this are emboldened to add more directives, get spicy with how they implement things, and try expanding on their techniques into the future. A stagnant implementer culture that always wants to reach for assured, standards-mandated things is no fun in a world as vast and as lovely as Computing. And, of course, having dreams and realizing them means that all of us, together, get to see…
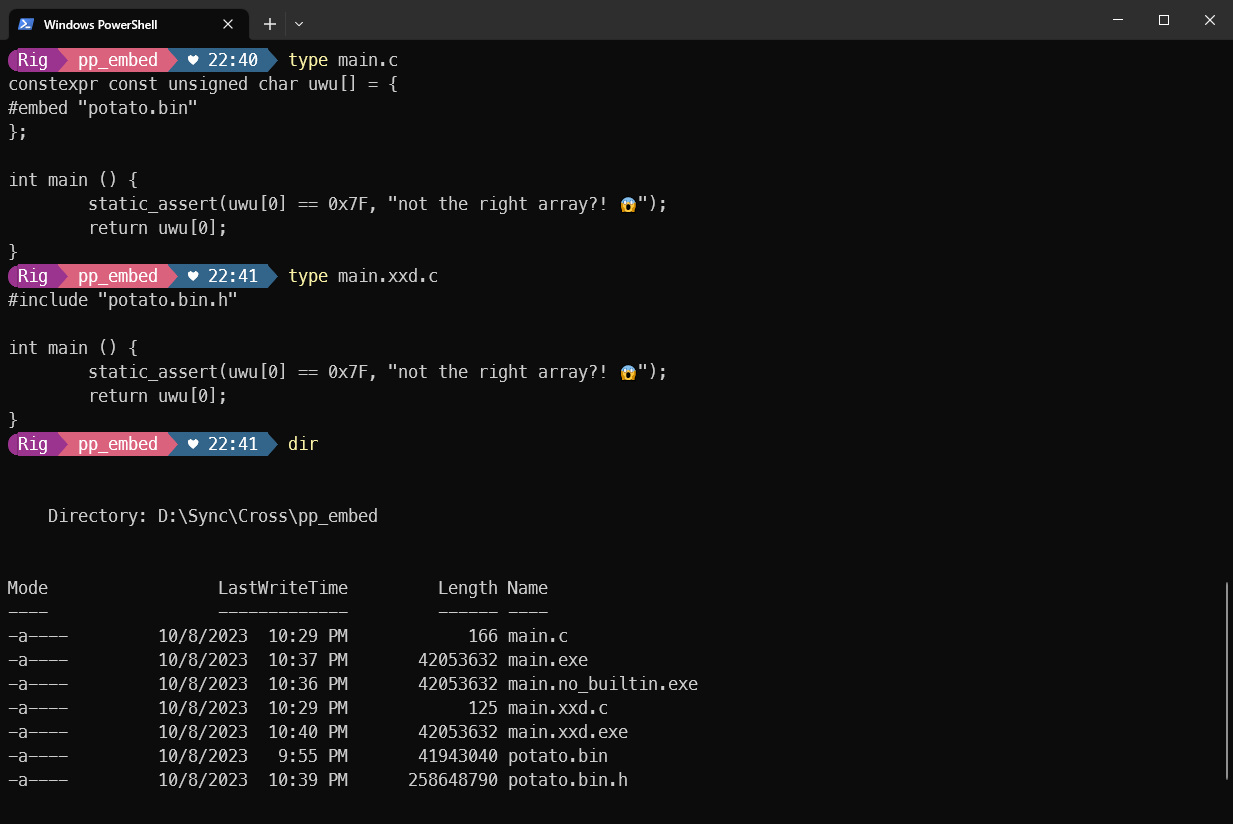
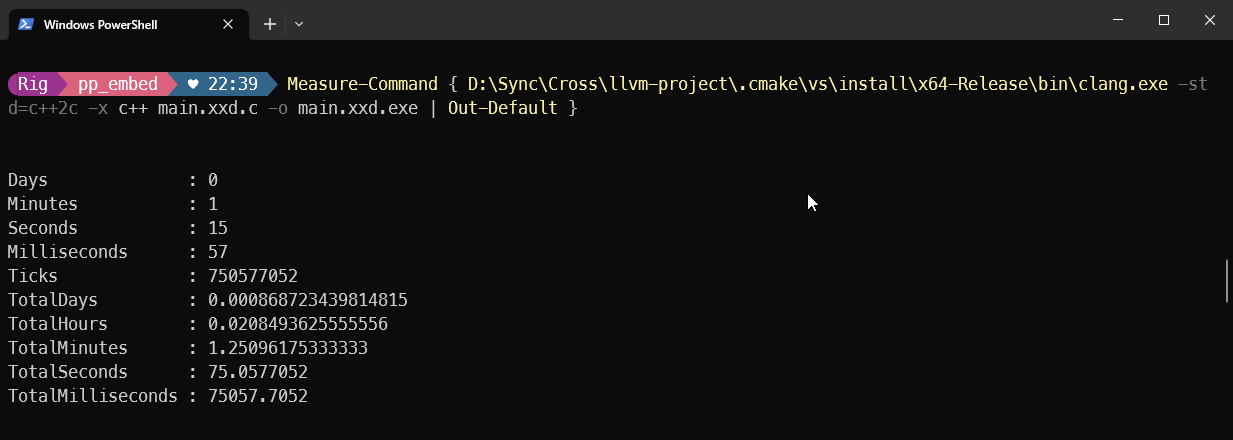
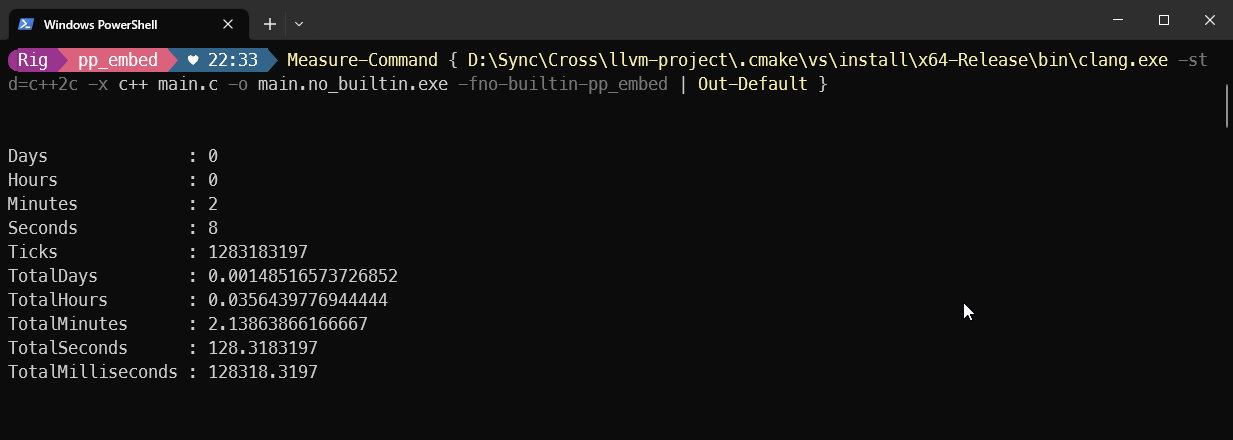
Just how much faster things can be compared to the tools we’ve been using for 40+ years:
A better future is possible. A future that’s at least 37x as fast as the one we’re living in. We just have to grasp it.
With our own two hands. 💚4
Footnotes
-
Notably, C++ needs a cast to
unsigned charwith each integer literal due to its type deduction rules. Each element of the array is meant to be anunsigned charvalue, whereas a regular e.g.212is considered anintand might cause initialization of anunsigned chararray might not go well for uses ofautoor Class Template Argument Deduction (CTAD). ↩ -
This actually takes
CHAR_BITbits from the file, going from \([ 0, 2^{CHAR\_BIT} )\) for each generated integer constant expression. ↩ -
For example, a four-argument version of the built-in would take: the expected type of each element; the number of bits to use per-element (for the
width( constant-expression )parameter mentioned earlier); the filename as a string literal; and, the data encoded as base64 string literal. One could provide avendor::type(int32_t)attribute to demand thatsizeof(int32_t) * CHAR_BITbits are used. These are not implemented in the Clang branch we are discussing in this implementation, though I have successfully implemented it previously (with anystd::is_trivial_vtype, which includes literally all types from C). ↩