The Committee says these things do not exist. The Committee says these things are invisible, not our business, and not something we can or should talk about.
They lie.
The standard is haunted. I know it is. Especially by that Three Letter Demon. I never really talked about how it has plagued me — plagued us all — with its insidious presence. Always the looming and lurking danger of The Demon, fearing the rearing its ugly head. While lamenting its existence I could never face it head on to challenge it. It is only at the height of my isolation that I could no longer bear witness to the violence the Three Letter Demon did to our beloved programming community and, thusly, began to scheme to take it down. But before we challenge it, dear reader, it stands to reason: what exactly is the Three Letter Demon? And why does The Demon matter to C and C++? Let’s finally get through this, in full, with a little illustrative help from our favorite local cryptid, kismet! and Luna Sorcery.
Application Binary Interface

Or, as it’s more commonly known as, ABI. Before many of you reading this were even born, before many of you reading this even knew what a computer was, a contract was forged in blood. It is not one you get to make for yourself; in fact, your consent or knowledge of its existence is not required, nor is it, frankly, at all requested. Everyone relies on it, and yet even people who build their own C++(-alike) compilers from scratch are unsure that such a contract exists, or that they’re even playing by such rules:
C has an ABI to break?
— Sean Baxter, Author of the Circle Compiler, July 19th, 2021
It stands to reason most would not know of it, because it is not an agreement made between the code you write and the output you rely on or expect to see. There is no binding words between your code and the language/library (which is the Application Programming Interface, or API), but an exchange happens on your behalf. Implementers, with other implementers, declare that if something is shaped like “X”, it will behave like “X” under “Y” given conditions. It exists in the cracks and the nooks of an implementation where most language designers and code writers don’t really think about:
what, literally, needs to exist on my machine and happen for it to do the things I want to do?
How a function calls another function, how the stack is set up, where variables do and do not exist, how a data structure’s very bits and bytes are traversed. This is not a lamentation: nobody should have to think about such banal details to get any amount of serious work done! But like all abstractions, these things end up leaking. And sometimes, those leaks can take on a whole life of their own. Become alive. And that’s where the old contract comes up. Still, I should explain. What are some practical example of such a contract?
Let’s take a look.

ABI: An Illustration
To understand how ABI can affect us in C and C++, we will take a very real patch filed by an implementer of a C++ Standard Library. It’s about the iterator for a type:
Defaulting the copy constructor on its first declaration made it change from user-provided (and non-trivial) to implicitly-defined (and trivial). This caused an ABI incompatibility between GCC 8 and GCC 9, where functions taking a deque iterator disagree on the argument passing convention.
— Jonathan Wakely, libstdc++ Mailing List, October 29th, 2019
Can that really happen? Well, let’s look at the assembly generated for 2 hypothetical “iterators”, that fit the above bug report description. We’ll use 2 structures with the same stuff inside, but with a user-provided constructor and one that is defaulted. It looks a bit like this:
struct deque_block;
struct deque_iterator_one {
deque_block* thing;
int* current;
deque_iterator_one() noexcept = default;
deque_iterator_one(const deque_iterator_one&) noexcept = default;
deque_iterator_one& operator=(const deque_iterator_one&) noexcept = default;
};
struct deque_iterator_two {
deque_block* thing;
int* current;
deque_iterator_two() noexcept = default;
deque_iterator_two(const deque_iterator_two& other) noexcept
: thing(other.thing), current(other.current) {
}
deque_iterator_two& operator=(const deque_iterator_two&) noexcept = default;
};
extern int f_one(deque_iterator_one it);
extern int f_two(deque_iterator_two it);
int main () {
deque_iterator_one d1{};
deque_iterator_two d2{};
f_one(d1);
f_two(d2);
return 0;
}
We’re not concerned with the actual implementations of f_one and f_two. It’s in an external library somewhere, possibly compiled in a separate dynamically linked library (.dll)/shared object (.so). This is how f_one gets called by GCC:
xor edi, edi
xor esi, esi
call _Z5f_one18deque_iterator_one ; f_one(deque_iterator_one)
Alright, it uses 2 registers — edi and esi — and just passes the pointers on through to the function that way. (It xors the registers because it can detect at compile-time that the binary representation for the two pointers is all-zero nullptrs. A xor A is always 0.) What about f_two? Assuredly, the contents are the same, the compiler couldn’t possibly agree to a different contra-
pxor xmm15, xmm15
mov rdi, rsp
movaps XMMWORD PTR [rsp], xmm15
call _Z5f_two18deque_iterator_two ; f_two(deque_iterator_two)
That’s… definitely not the same assembly. Despite having identical structure and content, changing the copy constructor changes how it’s called. And not even changing the copy constructor in a way that truly matters: the behavior is identical in both forms: it does a bit-blasting copy operation! Right now, we have the functions — f_one and f_two — with two distinct names, and two distinct symbols in the final executable. But, you can imagine that if we had a single deque_iterator type, and added that copy constructor, GCC would violate the previously-established edi + esi register contract expected by the internals of some call f and instead start messing around with rdi and xmm15. This means that while the code compiles, links, and even runtime loads properly, the actual running of the code has a separate by-the-bits expectation. And when every single bit matters, it turns out everything else needs to be extremely well-defined when it comes to how the world works out. Argument placement, data layout, even the amount of stack space used and where things are kept changes based on making a fundamentally idempotent change to the copy constructor.
ABI: Even Simpler
Like the tweet above, some people think that ABI is explicitly a C++ problem. C is immune, after all, because it’s so simple! Sure, structures change, but there’s no overloading! No member functions! No constructors or destructors or alphabet-spaghetti nonsense like “RAII” or “SFINAE”, whatever the hell those are. And yet, in all Kernighan and Ritchie’s wisdom, we still have the same problem. In fact, we have the problem even worse than C++ does.
If you remember the example from above, we get these really filthy mangled symbols:
…
call _Z5f_two18deque_iterator_two ; f_two(deque_iterator_two)
…
call _Z5f_one18deque_iterator_one ; f_one(deque_iterator_one)
This means that, even if we named both functions just f in our code, at the symbol-level in our binaries it could tell apart a function meant for deque_iterator_one and deque_iterator_two. Again, this is because it’s grafted the name of the type into the final symbol that shows up in our binary:
…
call _Z5f18deque_iterator_two ; f(deque_iterator_two)
…
call _Z5f18deque_iterator_one ; f(deque_iterator_one)
How does this work in C? Ignoring the fact that you cannot name a function the same thing twice in C, it turns out we can get into trouble. Take, for example, a function that takes a long long and one that takes an __int128_t:
extern int fll (long long value);
extern int fi128 (__int128_t value);
int main () {
fll(1);
fi128(1);
return 0;
}
Once again, we inspect the assembly:
mov edi, 1
call fll
mov edi, 1
xor esi, esi
call fi128
We can see here that it uses 2 registers — edi and esi — for the __int128_t case, but only one — edi — for the long long case. If someone worked with a header file which used a typedef that changed in a function, we could end up with breakage. For example, the header file with a typedef of typedef __int128_t chonky_integer; was changed to typedef long long chonky_integer;, and we had a function that looked like extern int f(chonky_integer value);, we might end up in a situation where the compiled DLL/SO was expecting a __int128_t (both edi and esi should be populated) instead of a long long (just the edi). That’s a break, because if the function is expecting both edi and esi, and we only fill out the value for the edi register, who knows what’s in esi? This kind of breakage would be supremely hard to track, and might result in quite a lot of heartbreak later down the line as random values in esi change the way our program runs. The reverse situation is also terrible: if a DLL/SO was expecting a long long in edi, but we handed our value over in edi and esi, we’ve ended up in a situation where it’s impossible to use the full 128 bits of our value. Random truncations, numbers that aren’t signed being considered signed because they’ve got a certain bit-pattern in edi, and more shenanigans could all follow in a way that’s devastatingly hard to debug.
Note that unlike C++, C has no built-in protection against this because of the way symbols get mangled. If you have a function f that, in one place, presents itself as taking a single __int128_t and another that takes a long long, it can end up looking like this:
mov edi, 1
call f
mov edi, 1
xor esi, esi
call f
There is no “long long” or “__int128_t” baked into the names like there would be for C++. You just get the function name, and good luck to you if you don’t give it the right arguments. Without a header file or reverse-engineering the binary that f came from, you’d never know what it was calling or what it was expecting, which is genuinely terrifying. It also means that on an incredibly fundamental level - simple free functions! - C’s ABI is even more brittle than C++’s. The only reason people advertise C as having a “stable ABI” is because they mean “we exported a single function name and then proceeded to never touch it for a million years”. Just because the name never changes, doesn’t mean the functionality or the inputs never change: never having that reflected in the final symbol name means that C is more dangerous than C++ here. Changing a function signature in any way is a break: adding parameters, removing parameters, return types or even what passed-in pointers actually point to! All of these things can be done at the drop of a hat in C++, but tear C code in horrific ways.
Okay… But Why Does It Matter?

Well, for C, it means that changing anything - literally anything - is an ABI break. Change your typedef to be a bigger integer? ABI break. Fix your time_t structure to handle time with 64-bit numbers because Jesus Christ I Thought We Already Have Been Through This Please Stop Using 32-bit Integers For Your Time Structures? ABI Break (and probably a security issue):
musl 1.2 is now available and changes
time_tfor 32-bit archs to a 64-bit type. Before upgrading from 1.1.x, 32-bit users should read the time64 release notes.— musl libc, September 18th, 2021
And so on, and so forth.
For C++, they can change types that go into functions, add overloads, etc. because the type names are mangled with the function. But for solving that problem, they introduce a whole lot of new bits of fun that are just oh-so-delightful to have to deal with. For example, back in 2009, a paper — N2994, when we still used “N” paper numbers! — was accepted into the C++ standard. It basically went through and not only constexpr-ified many random bits in the C++ standard, but added the property that some iterators were trivially copyable, copy constructible, and destructible in typical cases. This meant that, effectively, these types would always be extraordinarily cheap to copy/move (often just bit operations) or destroy for their respective platforms. It went in. And then a strange e-mail popped up nearly 10 years later:
[isocpp-lib] N2994 was an ABI-breaking change to istream_iterator
… Huh? It had been 10 years: July 19th, 2019 is when this e-mail dropped into my inbox. N2994 been approved a long time ago! How do you have an ABI break from a pre-C++11 paper? This was before even my time, before I was even that into computers! And yet, this was exactly this case. It was similar to the deque_iterator case, just like outlined above: hand-crafted constructors prevented it from being a trivial type.
Some debate ensued. Thank God, we legitimately just had better things to do at the time: this was ~2 meetings before the final C++20 Prague Meeting, which was the last in-person meeting the C++ Standards Committee has had since (* gestures vaguely towards Outside *) happened. The thread ultimately fizzled out as other things were focused on, a Library Working Group (LWG) issue was never filed, and std::istream_iterator<some-trivial-type> as far as Standard C++ is concerned remains std::is_trivially_copy_constructible_v. Of course, this tiny detail has made it so some implementations - like GCC - just don’t conform out of fear of the same bug that deque_iterator suffered from above.
The worrying part about this is how, retroactively, long-accepted work done on the C++ Standard can be threatened if an implementation forgets to make a change before they flip their ABI switch. In this case, we very much just haven’t done anything. Whether that was an intentional choice to just not bother, or an accident that I may unfortunately be roundabout-informing the original submitter that they can, in fact, grind this ABI axe with the C++ Committee if they remember to pick it up, is up to speculation. In my heart, I feel like this current situation is the right choice: the Standard makes a guarantee and libstdc++ just can’t meet it for legacy reasons. I do not want what happened to deque_iterator happening to istream_iterator, no thank you: I prefer my calling conventions cheap and my code lean, thank you very much! Of course, this is a situation where the ship has already sailed. But…
what would happen if you weren’t 10 years late to the party?
Building a Graveyard

Most of the time I’ve talked about ABI, it has usually been a casual mention, in the context of some other fight or some other larger problem. But here, we’re going to talk about strictly ABI. Specifically, what happens when the ABI not only comes from the past, but also invades the present and future to stop us from doing things in C and C++.
From The Past
There are a lot of choices our forebears made that we are now eternally responsible for when it comes to ABI. One of the biggest examples of such are things like C’s intmax_t, or C++’s std::initializer_list and std::regex. Because of implementation choices that are not at all mandated or even required by the C or C++ standard, we get bound to either a lesser quality of implementation or get locked out of improvements the industry has long-since embraced, forcing us to keep things terrible.
C - intmax_t, strcpy, and Literally Everything Else
I’ve written about intmax_t, explaining how we’re so unbelievably doomed when it comes to trying to upgrade intmax_t, and how that’s tied to various parts of C and C++ processing. We can’t have integer literals larger than intmax_t, and since that means we’re stuck at long long for most architectures that means you can never write 128-bit or 256-bit literals. It means std::numeric_limits<T> can never have implementation-defined integer types like __int128_t work with them by-default because that’s technically a violation of the statutes, since every single integer type that is compatible with std::numeric_limits<T> needs to have a size less than or equal to intmax_t.
The worst part is, it results in a LOT of wasted time:

This was from a presentation on the subject to the C Committee at the beginning of September during a virtual meeting. We’ve wasted no less than 5 papers trying to (and failing to) solve this problem, and if we intend to solve it there will be more papers that come along the way, some of them soon. Some parts of the intmax_t problem have been solved: for example, the Specific Width Length Modifier was added to C to solve the problem of printing arbitrarily-large-sized integers that the implementation can handle printing.
The status-quo remains, however: despite it being common practice amongst libraries like musl libc and glibc to provide weak aliases and other forms of implementation-specific indirection over functions to prevent ABI problems (and allow for safe overriding in select circumstances), the standard itself is bound by the simplest possible implementation of the C Standard Library. Because there is no standard-mandated solution for name aliases / indirection in C, or ways to provide name-mangling on your own, someone can create a POSIX implementation that takes all of the names in the C Standard very literally. All of the names — strcpy, strcat, memset, gets_s, what have you — appears exactly in the system’s globally shared symbol table. That means that even if a specific application wanted to, say, request a printf that’s capable of printing int128_t or has special format modifiers for certain structs, that printf has to be globally upgraded and agreed upon by every single program in the system that uses the C library.
Yeah.
Dear reader, you can likely see why this becomes a problem when you have a system that becomes older than a few years, or you have a package manager running for said systems running for any length of time. Everybody has to agree in perpetuity, all the time, from the time someone settles that implementation’s global table onward. And that really means whoever gets there first wins, not whoever has the best idea or works the hardest to improve their runtime. This is why Victor Zverovich found it easy to kick the C and C++ standard libraries’s butts:
Even formatting such simple things as hour:minute with format string compilation in {fmt} can be almost 10x faster than
ostringstreamand ~2.5x faster thanprintf=)Victor Zverovich, September 3rd, 2021
If we can never improve what we have without fear of binary break - on top of actual source-breaking changes - it doesn’t matter how carefully people craft design, because someone can and will always be able to completely outstrip that body of work, even if theoretically you could do better under the old design constraints. As the system becomes larger, bug-compatibility becomes more important than performance or correctness, and serving your life up on the altar of 50 year old design decisions becomes harder to resist with each progressively larger system rolled on top of another.
The same thing happened with Nested Functions in C, too.
Nested Functions are an ABI Break?!
Unfortunately, yes.
Nested Functions are a very pretty GCC extension that takes the natural form of a function definition and extends it to exist inside of other function calls, allowing you to reference local data in callbacks:
int main () {
int x = 1;
int f (int y) {
// a nested function!
return x + y;
};
return f(1);
}
Nested Functions in GCC, if we were to standardize them, can result in an ABI break if we try to change their behavior or fix the potential security issue with them. As I detailed in another article where I went into depth about the various ways to handle “function + data” in C-style APIs, Nested Functions are implemented as a trampoline jump with an executable stack in the most general case when no special optimizations can be taken. Executable stacks are a basic security issue: for some people they’re not that important, for other people it makes Nested Functions dead-on-arrival. Strangely enough, GCC supports other languages - like Ada - with Nested Functions that can and do perform the same computations as their C and C++ forms. To do so, Ada uses an implementation technique called Function Descriptors, which are inherently safer and can handle all of the cases that Nested Functions need without making an executable stack. Unfortunately, differentiating between the executable stack technique and the function descriptor technique requires setting a bit that is always off (0) in function pointers to instead be on (1). And you’d think that would never matter,
except it does.
Martin Uecker tried his best to create a solution that allowed for general-purpose usage by following Ada’s implementation technique:
… You pass
-fno-trampolinesand it would use the lowest bit to differentiate between a regular pointer and a descriptor (based on what Ada does). It still has run-time overhead and ABI issues.Martin Uecker, July 17th, 2021
Unfortunately, that’s not how function pointers are expected to be called in C. Even if the bit was “always zero” before, there is an implicit, binary expectation in every single C-derived program that you can just blindly reinterpret the function address bits as a function call, set up the stack with the arguments, and jump right on over. Altering that bit means you may attempt to call a function at an improper alignment, resulting in All Hell Breaking Loose. So, you need to mask off the bottom bit - something no binary is currently doing in the wild - check if that bottom bit means you’re doing Special Function Descriptor Things™, and then proceed with the function call.
So, it’s a binary break to do it the function descriptor way! 🥳
Why is this a problem, though? After all, it’s just GCC’s extension with the security issue! Well, as per usual, syntax means everything. Because GCC “stole” that syntax for its extension, if we standardize something with the same syntax but different semantics, that’s a behavioral break for GCC. And, it only gets better if we try to smooth the problems over! If we maintain all the same semantics / behaviors, we then have to contend with the fact that GCC has, for some ~23+ years, been shipping this syntax with an executable stack. Either we take it as GCC’s done it into the C Standard and condemn the world’s largest/prolific C compiler to its executable stack and security failures (including that code not being allowed to run / load on multiple different platforms from the get-go), or we demand they make an ABI break about the way the world’s most basic unit of reusable computation — the function call — is done!

Yeah, I didn’t think that was going to fly either. So, even if I like Nested Functions and their syntax, thanks to what GCC has done, we have very little in the way of remedies for this. The ghosts of the past continue to haunt the present and future of C, and continue to cause us undue harm to the language’s evolution. C isn’t the only one in its language and library to fundamentally ruin present and future directions from past choices, though!
Regex
A long time ago, C++ standardized what was effectively boost::regex with some tweaks. Support for it was spotty: at one point regex_match in GCC was just a function whose entire body was just return true;. Even after it was finally implemented, std::regex has some of the poorest execution time, throughput, and compilation time known to mankind:
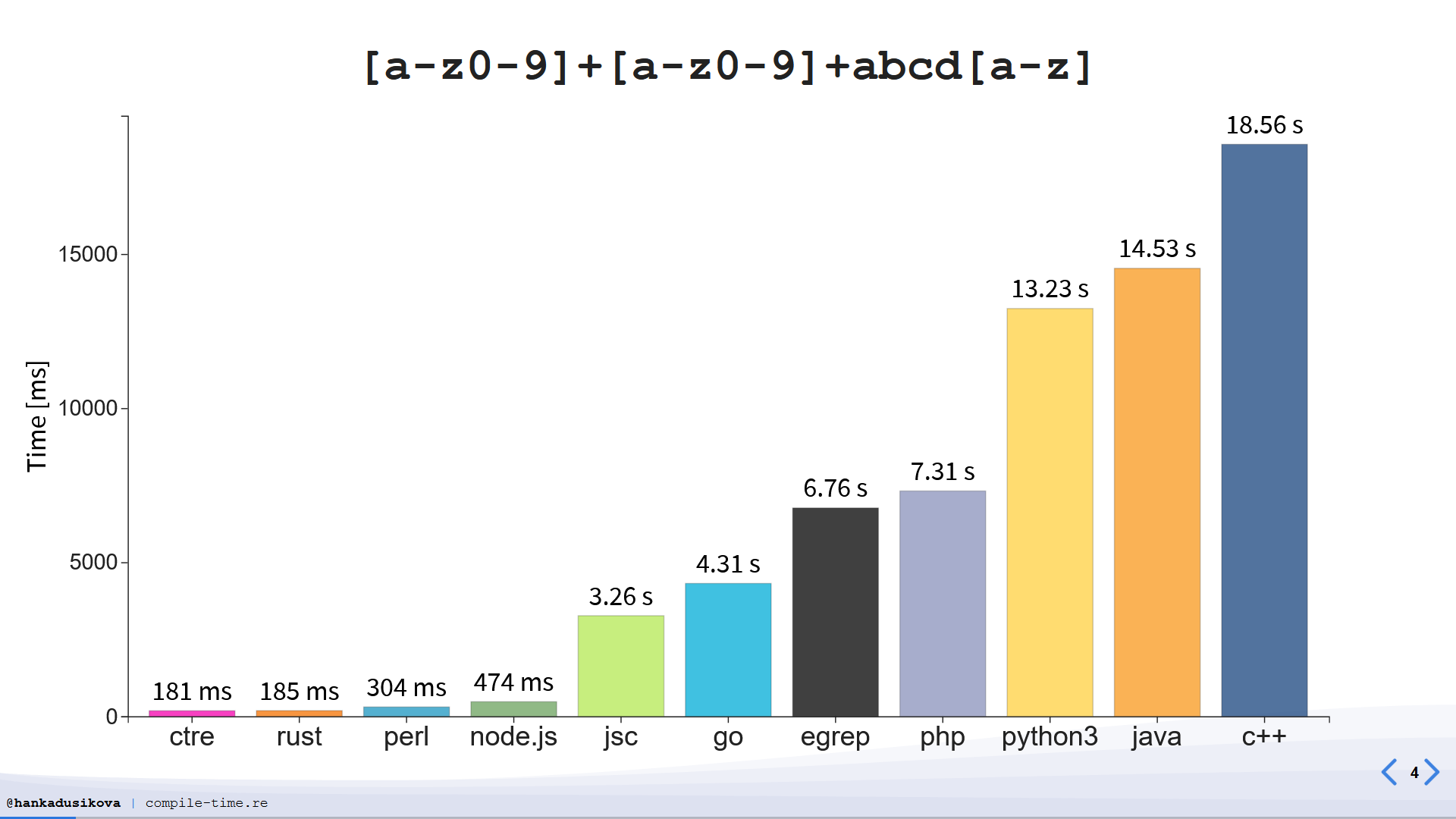
Nominally, many people have suggested changing std::regex in ways that would, at the very least, make it more useful. After all, maintaining a regex engine is basically its own full-time job: but, if someone’s going to at least ship a dubiously correct implementation, it should at least be useful, right?
… Right?
The problem with wanting some of that useful stuff is that the things done in these poor implementations are ABI locked-in. Did you want to have a std::regex::multiline constant in an updated C++17 implementation? That’s an ABI break. Did you want to have a new mode with specializations for handling UTF-8, UTF-16, and UTF-32 encoded text? That’s an ABI break, even when you deliberately avoid touching any existing template specializations like wregex_match. For example, MSVC uses the options flag and stores it in an internal template parameter before exporting all of the interfaces into DLLs. Adding new options means changing the syntax_option_type value in that internal template parameter, which gets mangled into the templated function names of the secret implementation sauce. That means that making any changes to this syntax option breaks existing MSVC code when an older Standard Library is linked with newly built applications using upgraded standard library headers. The secret implementation sauce is loaded but without a proper match for any new values added to the option type, resulting in either load time failures in end-user machines or more visceral schisms when pointers to specific functions point to things that don’t actually exist, just like in the simpler examples above.
Sure, C++’s std::regex is terrible. Having some ~4 different flavors of syntax and various options as part of the syntax_option_type is terrible design, and we should never design something that way again. But the response to papers and proposals trying to steadily dig us out of this hole is to bring up ABI blockers and cite how much we don’t like std::regex’s design as a whole, while preparing to mark it for deprecation:
The SG16 poll in favor of deprecating std::regex was based on design and evolution related concerns. Volunteers agreed to bring forward a deprecation paper.
You’ll note part of the magic words for doing this deprecation is “Do we want to recommend deprecation of std::regex without guarantee of replacement?”. That means that, if we do deprecate it, there’s no guarantee you’re going to get a replacement regular expression library back in the Standard. Maybe someone like Hana Dusíková will bring a paper forward for something like CTRE. Maybe we can ask the author of P1844 — Nozomu Katō-san, a man we’ve already disappointed despite him doing the proper job of shipping and gaining usage and deployment experience with a standard-like regex library supporting Unicode-encoding-aware iteration — to just make something completely new. Or, we can get absolutely nothing, and someone will bring a paper after a standard or two (3-6 years) to go ahead and remove std::regex from the Standard Library.
This becomes the everlasting problem in most Committee discussions when a proposal (might!) involve an ABI break. We could just deprecate std::regex and propose std::regex2, but the moment that proposal comes out everyone gets annoyed about the name and “why can’t we just fix regex?!” and then the ABI people pipe up and around and around the circle goes. It’s never about what you can and cannot have, at the end of the day: you can easily just fork the entire Standard Library into std2 and have a blast and fix all of your terrible inconsistent design choices at a nice and reasonable pace. No, the problem is that we explicitly get in the way of such initiatives on principle (e.g., one of the previous LEWG Chairs considered their highest accomplishment “killing std2”), which would be fine if we actually had a path forward for existing designs. But for many things that are not purely additions, we run into currently existing implementations,
and it can block a lot of progress.
Remember that at no point was Nozomu Katō-san in the wrong here. They did everything we normally ask of a person engaging with the C++ Committee: write a proposal, submit it to be presented with a champion, have an existing implementation with usage and deployment experience, and have technical wording that can be improved by wording experts to go into the C++ standard if it is not already good specification. There was no reason Katō-san failed other than the inability of the existing implementations to cope with ABI instability or wanting to nitpick std::regex’s existing design. For example, some people complained that std::regex can work with any bidirectional iterator, and “honestly, who would do that or need that in this day and age? Who is going to iterate over a list<char>?”. Unluckily for this person, that criticism rings hollow in the face of existing practice in even modern C++ implementations of regular expressions. It’s also utterly reductive: linked lists and growable arrays exist on two opposite ends of the data structure spectrum. There is plenty of room for other traversable data structures in-between, including ropes, gap buffers, and more.
Nevertheless, we, as the Committee:
- took the contributions of someone who was, perhaps, one of the only Japanese developers not affiliated with any company by the Japanese National Body or the C++ Committee in general;
- that, fixed something in the language that has long been exceptionally busted (Unicode encoding-aware regexen);
- and, effectively ran them into the ground;
- for, a sequence of concerns completely outside of their design auspice (
std::regex’s poor initial design) and implementation control (ABI concerns from implementers).
… Nice?
It becomes harder and harder to defend a “no improvements, ever” model to the standard as we continue to pile the bodies higher and higher of those who try in reasonable good faith to make this standard a better version of itself within the rules and confines we place on individuals.
And somehow, we wonder why people spend their time proposing new features/additions rather than fixes to old things! Like std::initializer_list, for example, which has been its own quiet little blood bath.
You Shall Not Move
C++11 introduced both std::move/move semantics, and std::initializer_list. Unfortunately, std::initializer_list was move-resistant: the backing memory of the compiler-generated std::initialier_list data was always some fanciful, magical const-qualified array of stuff. That meant that the data coming out from a std::initializer_list’s iterators upon dereference were const T&, not T&. It is effectively illegal to move from that storage, even if you were to cast it, because sometimes compilers “optimize” the storage so that it only creates it once, even if it’s used multiple times in a loop. For example, this code:
#include <string>
#include <vector>
#include <cstddef>
int main () {
std::vector<std::vector<std::string>> string_buckets;
for (std::size_t i = 0; i < 24; ++i) {
string_buckets.push_back({"hello", "there", "friend", ":)"});
}
return 0;
}
need not create a fresh std::vector<std::string> on every iteration, to then copy into the string_buckets. On the contrary, this is a viable compiler transformation (done by hand to show what can happen):
#include <string>
#include <vector>
#include <cstddef>
int main () {
const std::vector<std::string> _MagicCompilerStorage[1]{
{"hello", "there", "friend", ":)"}
};
std::vector<std::vector<std::string>> string_buckets;
for (std::size_t i = 0; i < 24; ++i) {
std::initializer_list<std::vector<std::string>> _MagicCompilerInitList
= _MagicCompilerInitializerList(_MagicCompilerStorage);
string_buckets.push_back(_MagicCompilerInitList);
}
return 0;
}
This is, of course, a huge problem if you want to initialize a container or other cool type with an initializer_list that would contain, for example, std::unique_ptrs or similar. After all, it’s read-only, const memory. You can’t move out of it; that’s the whole point! There were several papers that attempted to fix the problem, from introducing specializations rules, trying to introduce special rules instead, to trying to find new types to use, to ultimately - and most recently - just trying to fix std::initializer_list itself, directly. After all the early decisions to try and find a new type and make it clear that it was not going to be accepted, and new rules weren’t going to be allowed. Why not fix std::initializer_list itself-
Hey, That’s an ABI Break!
…

Yep! Despite getting a handful of papers before C++11 shipped to fix the problem, we did not in fact fix the problem. So when I took my naïve self to represent the paper on behalf of Alex Christensen, and I was informed that moving from the storage that was “hoisted” out of the loop by the compiler in an effort to save on space / constructions, I was initially like “oh, I’ll just write a proposal for std::initializers!”. That is, in fact, what I very foolishly e-mailed the author:
Dear Alex Christensen,
The current revision of this paper has hit an unfortunate, show-stopping roadblock: ABI.
c++23.cpp: (compiled with -std=c++2c or something)
DLL_EXPORT void initializer_list_stuff (std::initializer_list<int> il) { *il.begin() = 500; }c++17.cpp (compiled with -std=c++17)
#include <c++23.hpp> int main () { std::initializer_list<int> kaboom{ 1, 2, 3 }; // stored in const memory initializer_list_stuff(kaboom); // modifies const memory :( }I see the way forward for this paper being that we create a completely new type:
std::initializers<T>.std::initializers<T>is non-const and does all the change in this paper. std::initializer_list is left alone entirely.…
Little did I know, that that was exactly what David Krauss and Rodrigo Castro Campos had already been trying to do in the first place, just they were doing it over 10 years ago. I was just walking back that idea, all over again, in the exact same Committee, with almost all the same people who were there when Krauss’s and Campos’s ideas got shot down. Except now, it was about ABI! Even if I could make a convincing design argument (and I DID, which is why it almost went to the next stage until the ABI concerns were brought up!), it would always die because of ABI, plus whatever reasons prevented us from making movable_initializer_list<T> in the first place. Every time I talked about these things in the Committee, every time I spoke with C++ experts inside of the Committee, it was always “ah, well, we just did not know any better and did not know how to combine the ideas at the time, a shame!”. Nobody ever admitted “oh, we knew, we just were not going to accept it in that form. :)”. One of these explanations makes it seem like the Committee is just a bumbling oaf who needs a little help, of which I was happy to supply. The other is far more deliberate and means I should not carefree-offer to champion someone else’s (small) paper who is about to run headlong into a 16 year old intentionally-manufactured problem.
But then again, it’s not the first time I’ve run headfirst into WG21’s ability to memory hole an explicit design decision.
Something something history, something something repetition!
std::polymorphic_allocator
By now, you’ve got the gist of how this is going to go. It’s another ABI break, but this time it’s actually a little worse than the usual ABI break. The worst part about this is not that somebody proposed something new: oh, no. We just standardized something using the same design that, at the time of standardization, we knew to be a terrible idea for extensibility. Here’s std::memory_resource’s interface, private virtual and public functions:
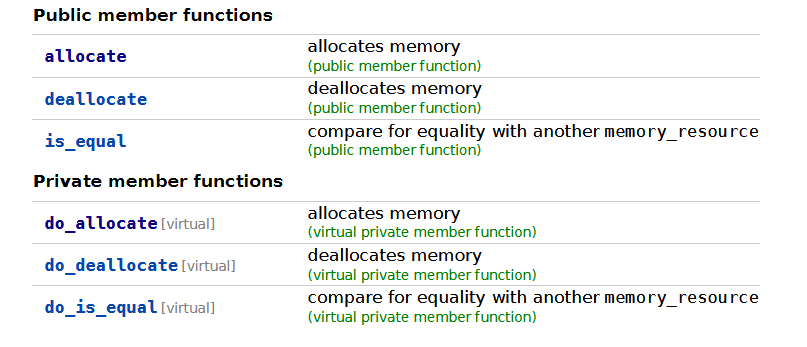
You’ll notice it does this funny thing: there’s public member functions on the memory_resource, but they call out to private virtual functions! That’s kind of neat. And it allows various different kinds of std::pmr::memory_resource-derived types, like std::pmr::new_delete_resource. But… there’s something about this design which feels familiar. Have we seen this before? It was standardized in C++17, but the design felt… old? Aged, in a w—
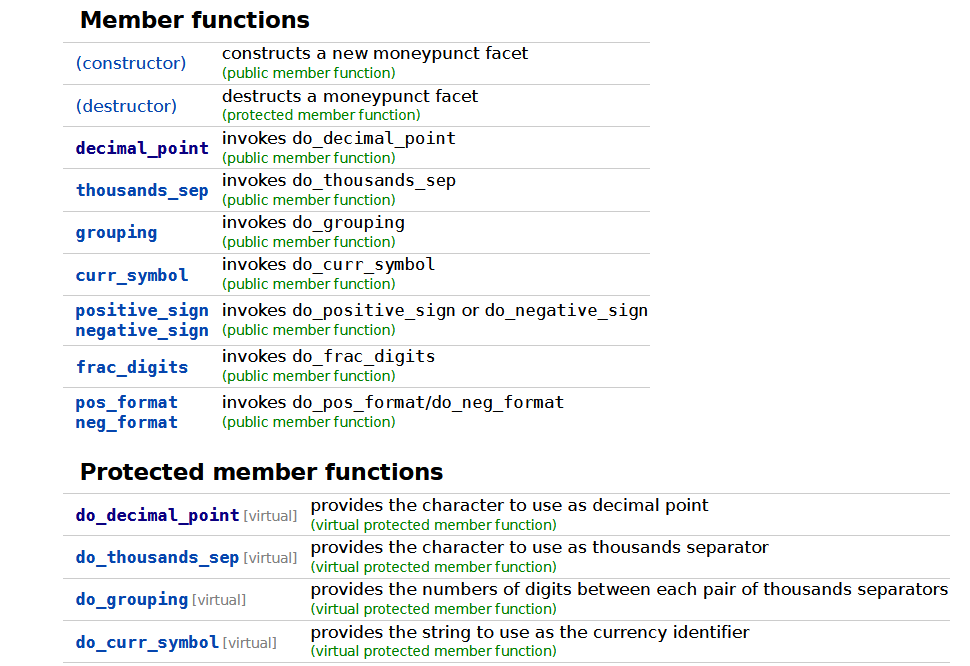
… Oh. My god.
It’s std::moneypunct.
std::memory_resource — and, consequently, the top-level polymorphic allocator design — is based off of the C++98-era locale design! Now, you may be wondering why this is terrible. After all, even if locale (and its uses in <iostream>) are dated and a bit bad, if the shoe fits for memory_resource it works out, right? Well, one of the BIG reasons we (try) not to put virtual functions into C++ interfaces anymore (at least not in standard library types at least!) is that virtual functions are one of those things that absolutely solidify not just an API, but an ABI.
Hard-Wired for Failure
As a quick primer, virtual functions generally create what’s called a “Virtual Table”, or “v-table” for short. All of the virtual functions on a class are stored in that v-table. If you have a derived class with new virtual functions, those get tacked onto the v-table. That virtual table is kept with each instance of a (derived) class object, so that it can use some fancy offset magic to know how to call the right function when you call a given virtual function. All good, right? Well, here’s the big problem: each entry in the v-table has an incredibly specific offset associated with it. When we tried to add new functions to std::moneypunct, and other locale facets associated with famous things like std::money_get/std::get_money, what folks realized is that developers had derived from things like std::moneypunct and added their own virtual functions. That means they tacked new things on to the already-existing v-tables from their C++ Standard Libraries. Those new things they tacked on had an extremely specific offset in bits from the v-table’s base address.
You see it, right? Where this is going. If we, as a Standards Committee, add new virtual functions to the base object of std::moneypunct or std::memory_resource, we risk taking someone’s derived v-table, and shoving their offsets down into later entries at later offsets. It’s just how it is: the base table needs to have more stuff in it (say, 6 virtual function implementations instead of 4 virtual function implementations). So the base table gets bigger, and it pushes some downstream developer’s v-table a little bit further off. If someone compiles a new header with an older version of the standard library, and the function is called, the entry at the wrong offset will be accessed in the v-table and called, and…

Yeah, that was my face too. This is just how it is, because we cannot for the life of us handle ABI breaks. We knew this to be a bad idea at the point it was proposed, too, because by this time we had fully uncovered how inextensible and untouchable iostreams existing locale settings as a whole were, especially std::moneypunct. But, more importantly, we also knew that our allocator API was incomplete. As far back as 2004, Howard Hinnant wrote proposal for both C (N1085) and C++ (N1953). This was followed-on by Ion Gaztañaga with another C++ proposal (N2045), then Jonathan Wakely, and a few others in-between these proposals that all indicated that the allocator model we had adopted into the standard library was woefully incomplete for real world work.
By standardizing virtual functions in std::polymorphic_allocator and std::memory_resource, we effectively cut off those avenues of improvement from the standard. Changing virtual functions is a hard ABI break, and no one has successfully added more virtual functions to existing virtual functions once we understood that there were consequential ABI breaks involved. To standardize a known-bad interface and thereby lock out all improvements to polymorphic allocators was an avoidable, fundamental, and unfortunately recent (C++17!) mistake that we now have to just live with in perpetuity.
And when I say in-perpetuity, I mean that in a very visceral and immediate sense.
Haunting the Present

One of the core problem with ABI is that it very much affects how the Committee works and designs things. It also means that improvements often get sidelined or ignored because it can’t be feasibly done without an ABI break. Sometimes, there are fixes that can be done, but only partially. So, for example, while the standard adds allocate_at_least(size_type n) to the current std::allocator, nothing can be done for std::polymorphic_allocator because of the reasons mentioned. From a proposal that actually has a chance of making it into C++:
std::pmr::memory_resourceis implemented using virtual functions. Adding new methods, such as the proposed allocate API would require taking an ABI break.— “Providing size feedback in the Allocator interface”, P0401r6
And so… well, that’s that. Even if std::polymorphic_allocator is giving people huge gains in code — not because of the virtual interface, but because it comes with a few std:: available implementations for pre-created memory regions — it will never be able to realize any of the gains as we — finally — begin to add functionality called out by Howard Hinnant 17 years ago in proposals to C and C++. Even as allocate_at_least percolates through the Committee, we also miss both in-place expand and shrink functions for containers which can dynamically grow/shrink memory in-place, without reallocation, which is an incredibly useful property for single-memory-blob allocators which tend to pull objects from a singular region of memory. And if we ever properly propose expand,shrink, and potentially a reallocate function for our allocator model, std::pmr::memory_resource will continue to miss out on fixes, changes and optimizations. Which is likely what’s so depressing about me working up the courage to release my own ztd::vector and ztd::allocator that realizes some of Howard Hinnant’s vision, and what makes it doubly depressing to try and write a paper about it:

“Yes, we can realize these gains. No, they can’t work with polymorphic_allocator. No, I can’t do anything about it unless every implementation decides to break ABI at the same time. What do you mean my eyes are glassy and I have a far-off, broken look in them?”
It’s a demoralizing process, from start to finish, and almost makes a person feel like it’s better to abandon almost everything than stand there and fight with implementers. Of course, it’s not just allocators that get in the way of proposals. Even something as low-level as std::thread::attributes ends up getting ABI flack!
… Seriously? Attributes for Threads is an ABI Break??
In a very literal sense, no, no it’s not. You can’t break the ABI of something that does not (yet) exist. For those wondering, a proposal got circulated around to fix a common problem spoken about by Bruce Dawson: he wanted to name his threads so that he could keep track of them better, and std::thread didn’t let him do this. Corentin Jabot picked up the idea, and put it in a new paper called “Usability improvements for std::thread” (P2019). In it, it contains a simple structure:
class thread::attributes {
public:
attributes() noexcept = default;
attributes(const attributes&);
attributes(attributes&& other) = default;
attributes& stack_size(std::size_t size) noexcept;
attributes& name(std::span<const char> name);
attributes& name(std::span<const char8_t> name);
implementation-defined __name; // exposition only
std::size_t __size; // exposition only
};
Wouldn’t you know, the first complaints are about ABI. “If I implement this structure to contain exactly a name and exactly a size, what happens if I need to add more things to it later?”. Which is baffling to me, sincerely. YOU are the implementer. You’re the one that sets the tone here. If you expect pthread to add some new functionality, or WinThread gets a boost in features, or you want to add implementer-specific functionality to this with a special macro to #ifdef on it’s existence, you could easily make room for that. The actual member variables are not even present from the paper’s wording: they’re explicitly “exposition only”. That means you can layout the class however you like, set whatever defaults you like, go nuts. Thread/core affinities and other attributes could easily be supported. At no point do you have to sit down and take any guff from anyone, because you — the implementer — are in control of the implementation!
But proposal authors are now responsible for maintaining the ABI of every single implementation out there when they decide to implement things in the most future-incompatible way possible.
Even the people designing Win32, POSIX, and Ethernet protocols had the wisdom to say “you know what? We might need some of these bits some day: let’s mark certain things reserved/unused in their values in the structure so we have some room to work with here”. Even if they never ended up using it, at least they had some kind of plan.
C++ implementers have no plan.
Even when the wording isn’t strict, even if we don’t provide literal by-the-letter commandments, implementations are more than content to shoot themselves in the foot. Or, worse, they are content to threaten to shoot themselves in the foot and make everybody else pay for it later. The natural consequences of this is that instead of a normal struct with friendly builder syntax, we now have to wait for a paper redesign where we do something silly instead. One of the explored designs the paper author disclosed to me would be something like adding std::thread::name_attribute_t, std::thread::stack_size_attribute_t types, and then you have to pass an instance of the attribute type to the thread constructor, plus the actual value. Like some sort of unholy amalgamation of named arguments:
#include <thread>
#include <iostream>
int main () {
auto thread_function = []() {
std::cout << "Hello from thread!" << std::endl;
};
std::thread t(
std::thread::name_attribute_t{}, "my thread",
std::thread::stack_size_attribute_t{}, 1'024,
thread_function
);
t.join();
return 0;
}
Corentin Jabot may introduce std::thread::name_attribute as an inline constexpr instance of the std::thread::name_attribute_t type, so that you don’t have to use {} to create an object every time. But this is ultimately the kind of workarounds we have to engage in just to get away from things like ABI. All because we can’t even do things like add a member variable to a structure without expecting the entire POSIX global table to collapse in on itself, or Microsoft to fail with its implementation and not make room for other variables in the structure.
Hey! That’s Unfair to Microsoft
You might say that. Unfortunately, we have a lot of experience with Microsoft, in fact, doing exactly that! You would think that someone who came late to the ABI game would be a little bit more prepared for what it means to take their time to lock things in so they don’t end up in the same situations as libstdc++ or libc++. But Microsoft did not only fail with ABI, they did it in a space where they had all of the right tools to make the right decisions.
And somehow we still had a bit of a… kerfuffle, anyways.
A Brief History of fmt
If you’ve been living under a rock, std::format is the biggest thing since sliced bread to come to the Standard Library. Victor Zverovich’s proposal for std::format was based on his wildly popular fmt library. With so much industry experience and implementation experience, it was a clear candidate for a big C++ Standard Library feature that checked all the boxes. It also solved a long-standing problem, which was that iostreams was kind of garbage. While Victor didn’t solve the I/O part of iostreams, he did solve the formatting and printing bit quite thoroughly and to basically everyone’s satisfaction.
fmt became std::format in C++20. Victor even changed the license of his code so standard library vendors could immediately pick up his code and use it, or at least just read it. This is quite frankly above and beyond how almost every single other proposal has gone into C++, with the exception of Boost utilities (wherein many standard libraries just hoisted the code right out of Boost). There was, of course, one issue:
Chrono, and Locale
One of the things we noticed while preparing std::format for release is that many time spans from std::chrono did not have formatters for them. A last-minute paper from Victor, Howard, and Daniela added chrono specifiers to std::format. Victor implemented them, shipped them, and it was a good deal. The only problem is it violated one of fmt’s biggest tenets: no format specifier would be locale-sensitive by default. You had to opt into it, and the chrono formatters were NOT that. Which made for an interesting pie-on-the-face moment, because one of the National Body members complained about locale being used in fmt:
It’s sad that the C++ SC decided to taint std::format with locale. 10 years ago, I noticed the necessity of char8_t and they didn’t listen, and now they not only think the locale is not considered harmful, but they also think locale helps localization. In reality, it’s quite opposite, the locale actively hinder the localization effort.
— Ezoe Ryou-san, February 15th, 2020
We, as a Committee, very staunchly pushed back on them:
std::formatdoes not use locale by default… It uses it only if you explicitly provide one.— Fabio Fracassi, February 15th, 2020
This was one of some 4 or 5 comments saying that. And, well, it turns out…
We were lying. 😅
Oops! Now, we didn’t know we were lying, it was very much a surprise when Corentin Jabot and several others figured out that the chrono specifiers were locale-sensitive by default:
In 27.12 [time.format] it is specified:
Some of the conversion specifiers depend on the locale that is passed to the formatting function if the latter takes one, or the global locale otherwise.
This is not consistent with the format design after the adoption of P1892…
— Corentin Jabot, LWG Issue 3547, April 27th, 2021
P2372 was written to fix it, since it was further revealed that the normal fmt library was in fact locale-independent, and that it was a breaking change to swap between the way fmt was doing it and the way std::format was going to handle chrono specifiers. But, well, we had standardized the inconsistent behavior in C++20, and…
“This is Going to be an ABI Break”

Welcome to Hell, population us. You might wonder how a paper being worked on barely a year after the release of C++20 can end up being an ABI break. This is where Microsoft and VC++ comes into play. See, Microsoft had very recently been guaranteeing ABI stability in their platform deployments. In years gone by, Microsoft would break ABI with every release and ship a new DLL. It was your responsibility to sync things if it truly mattered: this let them fix a LOT of bugs in their implementation, at the risk of needing people to either recompile or at least check things worked with an updated runtime. (Or to just keep shipping the old VC++ DLLs. Remember all those VC Redistributable Downloaders for v2011 and v2012 and v2013 and v2015, anyone?). These days, however, they started locking things down in their ABIs pretty much immediately. This is why a lot of bugs suddenly became no-fix, or were pushed back to a mythical and magical “when we break ABI” timeline. See, one of the things Microsoft wanted to do was have std::format. And not only did they want to ship a version 0 of their own std::format,
they wanted to mark it ABI stable right off the bat.
Hubris?
Dear reader, let me tell you that even if you are a multibillion dollar corporation, being so brave as to tell the world you’re going to ship a brand new API and on Day 0 mark it as “stable, forever” is the kind of stuff you’d hear amongst developers after they all ate the specially-baked cookies & brownies, and the hookahs came out.
Of COURSE we don’t lock in our version 0 implementations, especially not for a sits-beneath-all-libraries library whose sole constraint is “stability, for the rest of your f[CENSOR]ing existence”! But Microsoft tried it. Oh, they tried it. When P2372 came out, everyone was freaked out because Microsoft started posturing that they were going to ship std::format, their first iteration of its implementation, to the whole world and mark it ABI stable while following the C++20 wording to the letter. That meant they were going to actively enshrine the design mistake from the std::chrono formatters: locale would be used by default, Ezoe-san would be completely within his rights to deride std::format, and we would be permanently made liars in the face of the entire C++ community while breaking Victor’s own fmt library in behavior.
The amount of effort that went to save Microsoft from this decision was staggering. We:
- Constantly applied pressure to Microsoft to tell them NOT TO DO THIS, YE GOD!!;
- Victor quickly applied fixes to
std::format’s implementation ([1] [2] [3]) in VC++ himself; - I pointed out that I had an open report that would solve their issues of (compile-time) encoding conversions opened almost a year before they got into the mess with “how do we translate our
const char*string literals”; - Corentin, Victor, and several others went to bat over it inside and outside Committee channels.
Ultimately, we won the concession. When the new version of C++ released for Microsoft, their release notes contained this bit:
… you need to be compiling with
/std:c++latest…— Charlie Barto,
<format>in Visual Studio 2019 v16.10 Release Notes
This is a very small bit of wording, but important: Microsoft keeps things that are unstable out of its well-defined standards switches (such as /std:c++20). By only having it in the /std:c++latest switch, it meant they effectively agreed not to stabilize <format>’s ABI forever.
Thank God; crisis averted! … But yet, this left is a horrible taste in my mouth.
The Spooky Terror Behind the Actions

The ugly truth here is that we had to effectively convince a vendor not to do the worst possible implementation and shoot themselves in their own foot. Which is really quite remarkable! It’s one thing when, say, IBM or Intel shows up and says “we have a private implementation of X, we’d like to put it in the standard library”. It’s understandable if people mess that up, because they only hand us the interface and not the implementation. But this was a case where:
- Victor had published his library and had the correct behaviors in for years;
- Victor changed the license so vendors could not only look, but blindly copy-paste if they wanted to; and,
- Victor published several blog posts describing the implementation details and tradeoffs to be made.
At no point should anyone be stabilizing their implementation until they could prove it was at or better than Victor Zverovich’s fmt lib. And yet, that’s not what happened. Which begs the question: why did Victor spend all that time working so hard on the proposal, its fixes, and its percolation through the C++ Committee? If you work that hard and make it across the finish line and get it into the C++ Standard, only to have implementations both ignore your publicly available implementation and threaten to ABI stabilize the worst possible one so that the rest of the ecosystem suffers indefinitely, what is the point of standardizing a library feature in C++? Victor did everything right and completed the bonus material with flying colors. If Victor is one of the greats, up there with Eric Niebler and Stepanov in their capacity to save C++ with their work,
how should everyone else feel about approaching the C++ standardization process?
I must note that the really terrible part is that Committee members were willing to block things like no-locale-by-default fixes for ABI reasons. This also does not make any sense whatsoever: MSVC has been talking about how it has an ABI-breaking release coming “Soon”, and that they will deploy it when they’re good and ready. If you know you have an ABI-breaking release of your library coming soon, that means that ABI breaking changes aren’t even as bad as Microsoft could claim, because Microsoft actually has a version coming where they can fix their mistakes. libstdc++ does not have a planned ABI break: their policy is ABI stability, for the rest of their lives. I can see why RedHat or similar implementations would lodge an ABI objection. But, for a vendor with a planned ABI break to object to an ABI breaking change? That means that they condemn their future release to be worse, because they act against the very standardization of the improvements their own next-generation release would make use of.
The absurdity is only eclipsed by how profoundly harmful this behavior is to the whole of the C++ ecosystem.
Implementation Override

I am terrified, dear reader.
We already have people who are finding inefficiencies in the allocator models, exception handling, object model, calling conventions, storage sizes for classes, and ultimately the library implementations of C++. They’re regularly exploiting that in their languages for better performance and, on occasion, outstripping both their C and C++ counterparts in performance and correctness with readable code.
If implementations can do their worst to people’s hard work when it finally comes time to standardize it all, what was the point then? We have a Networking TS where people want to put it into the C++ Standard Library. What happens if libc++ phones their implementation in and does something bad? What happens if there’s a crippling security issue and it’s time to patch your standard library? What if we need to fix a longstanding design issue? Every implementer has effectively total veto power in what’s supposed to be a republic-ish system of representation, or at the very least can strongly threaten to wreck you and your work because they don’t feel like dealing with doing things in a mildly not self-sabotaging way.
Do you understand, the chains every proposal author is now bound by? The contract we all sign with our blood, sweat, tears, and — penultimately — our time? This is not even just one instance. Microsoft patently refused to honor the standard [[no_unique_address]], citing ABI concerns. Despite the fact that it was (1) a new feature and the standard had not rolled out yet at the time of their implementation, and (2) is an explicit request from the user. By willingly ignoring that attribute, they compromise everyone’s expected semantics and reduced what was one of the most important object-size-reduction techniques from an implementation reality to, once more, being just a shoddy suggestion. What’s worse is that they did not even implement full support for their own implementation-specific no_unique_address, which they spell [[msvc::no_unique_address]]:
#if __has_cpp_attribute(no_unique_address)
#define NO_UNIQUE_ADDRESS no_unique_address
#else
#if defined(_MSC_VER)
#if !__has_cpp_attribute(msvc::no_unique_address)
#error "MSVC does not have no_unique_address"
#else
#define NO_UNIQUE_ADDRESS msvc::no_unique_address
#endif
#endif
#endif
int main(int, char*[]) {
return 0;
}
This code errors with “MSVC does not have no_unique_address” on the latest release build of MSVC as of September 23rd, 2021. The one sole feature we have to test that MSVC — or any other implementation — does in fact have msvc::no_unique_address (or any other attribute) is busted. That means I need to go back to relying on ancient techniques such as #if defined(_MSC_VER) && _MSC_FULL_VER > 192930133 rather than just regular, standard techniques for checking for attributes. This, from an implementation that wants to attempt to standardize a known-poor implementation of <format> and then ship it to customers with an entirely straight face, while then turning around to challenge the Standards Committee on ABI concerns and summon up that Three Letter Demon.

Is this sustainable? Is this tractable, when every implementer can fuse themselves together to beat the crap out of a proposal even if it fits the design criteria and preserves the API space? Are we just supposed to live in perpetual fear that one day someone made an Oopsie Kapoopsie in their std::lock_guard implementation, and that there’s no way to fix it from now until the end of days? That even if we can do better on our own platforms, because the Big Three don’t want to be declared non-conforming, they can just continue to throw their weight around and complicate every proposal’s lifespan? That every proposal author must tremble in fear of those three letters? That we have to shake in our boots because our implementers can’t handle versioning a struct that they have reason to suspect might change for their implementation??
I am about to author one gigantic proposal for putting text in the Standard Library. I have authored no less than five videos describing the design, performance, tradeoff, and motivation. I have a boatload of documentation.
What happens when Microsoft decides that the worst possible implementation is what they should rush into their binaries and then declare it ABI-stable? What happens if there’s additional improvements that come beyond the initial proposal (of which there is a big chance, because this is for a fundamentally human aspect of programming, text!)? What happens if libc++ decides today is a good day to phone it in with respect to performance and then vendors standardize on their v0 implementation…? What if they decide to not read any of my documentation, as they had not read Victor’s documentation? What if they decide to ignore my videos, my lengthy design and performance explanations? Is what Victor went through what I’m supposed to look forward to, as someone who wants to contribute a large body of important work to C++?
No.
I refuse.
You cannot make me pay my blood for a contract with this insidious, ever-pervasive amalgamation, I was not even alive to bear witness to. I will not sit in every meeting and be endlessly bullied by implementations that do not know how to handle a problem they are the sole controller and proprietor for. It’s absolutely inane that even the most mundane of proposals can suddenly be ran through like a train wreck because the pinnacle of C++ and C experts cannot answer the question “how do I version something”. I will have a good standard library. It will meet my performance requirements. It will be correct. I do not care how many ghosts of the past there are. I do not care how many implementations exist where a person programming for longer than I have been alive made a sub-optimal choice one day and now we just have to live with that, for the rest of eternity. I will not be made to suffer someone else’s mistakes in perpetuity, while they also continue to make the same mistakes in egregiously flagrant fashions now and into the future.
I shouldn’t even be held back by my own mistakes from yesterday, what kind of world do we live in where we settle on a process so fundamentally against the human condition of learning and growing as an individual? Why would we prioritize a working process that at its deepest roots is so fundamentally against the living human being, and happier to dwell with the dead?
The binary banshees and digital demons of ABI will not overtake us. It will not trample over me, over my implementation. I will not be bound by the mistakes of people who know not my name, nor the names of the people whose life I aim to make better. The standard is for me too, not just Microsoft. Not just IBM. Not just Apple. I will not let ABI hold us perpetually at implementation gunpoint. One way.

Or another. 💚
P.S.: This ENTIRE article was because Luna Sorcery made a fun joke. kismet brought the whole thing to life with their amazing artist skills: you should go commission art from them, by the bucket load if you can!