Happy New Year! It is time report the results of the Array Size Operator survey and answer some comments people have been asking for!
The “What” Survey?
As a quick refresher:
#define SIZE_KEYWORD(...) (sizeof(__VA_ARGS__) / sizeof(*(__VA_ARGS__)))
int main () {
int arfarf[] = { 0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
return SIZE_KEYWORD(arfarf); // same as: `return 10;`
}
We were making a built-in operator for this, and that built-in operator was accepted into C2y, the next version of the C standard. The reason we wanted a built-in operator for this was to prevent the typical problems we have with macro, which (at least with the above definition) manifests a few issues:
- double-evaluation of e.g. getting the size of the 1-d part of a 2-d array
int meow[3][4]; /* ... */ SIZE_KEYWORD(meow[first_idx()]); - macro-trampling of normal user code without warning e.g.
#define array_size(....) /* ... /*(hope you weren’t using the word “array_size” anywhere important!); - and, better type safety e.g.,
SIZE_KEYWORD((int**)0)is a legal call given the above definition, and takes significant additional effort to improve type safety beyond the bogstandard basic definition.
Of course, the easier it is to understand the feature (3 bullets in a bulleted list and one code snippet), the more debate perverts crawl out of the woodwork to start getting their Bikeshedding-jollies in on things like the name. The flames of argumentation raged powerfully for an hour or so in the Committee, and the e-mails back and forth on the Committee Reflector were fairly involved. It spawned several spin-off papers trying to ascertain the history of the spelling of size functionality (see Jakub Łukasiewicz N3402: Words Used for Retrieving Number of Elements in Arrays and Array-like Objects Across Computer Languages), and even before hand had a survey conducted at ARM for it (see Chris Bazley’s N3350: Survey Results for Naming of New nelementsof() Operator).
I had my own opinions about the subject, but rather than wax poetical, I figured I’d follow Chris Bazley’s lead and just…. ask everyone. So, I just went and asked everyone.
How?
If you want to read the methodology for how all this worked, you can read the “Methodology” section of N3440: The Big Array Size Survey. We’re going to dive straight into the results, both the fluffy results and the serious results. There were 1,049 unique responses to the survey. A few had to be culled out. A few were partial responses; followup responses with those people (when possible) did not allow us to complete their responses, so they were recorded down as being neutral. You can access the data and see the Python Script that generated the graphs and the data at this repository. You can replicate the graphs NOT by running the script (that parses the raw data that only we have access to), but by doing the same matplotlib shenanigans after parsing the CSV. We’re not handing out the raw AllCounted data because it includes e-mail address, IP Addresses, and general location information, and we figure that’d be a big breach of privacy if we just handed all that shit over to anyone, so it’s all deleted now after outputting the necessary information instead!
The Respondents
We had quite a large selection of folks from almost every continent (except Antartica). The majority were Professional / Industrial software developers, and a LOT had 5+ years of experience, so we feel this is a pretty good selection of the C populace. Or at least, the population of C people willing to read my blog / check Reddit / check Twitter / check Mastodon / keep their finger on the pulse for a little over 1 month:
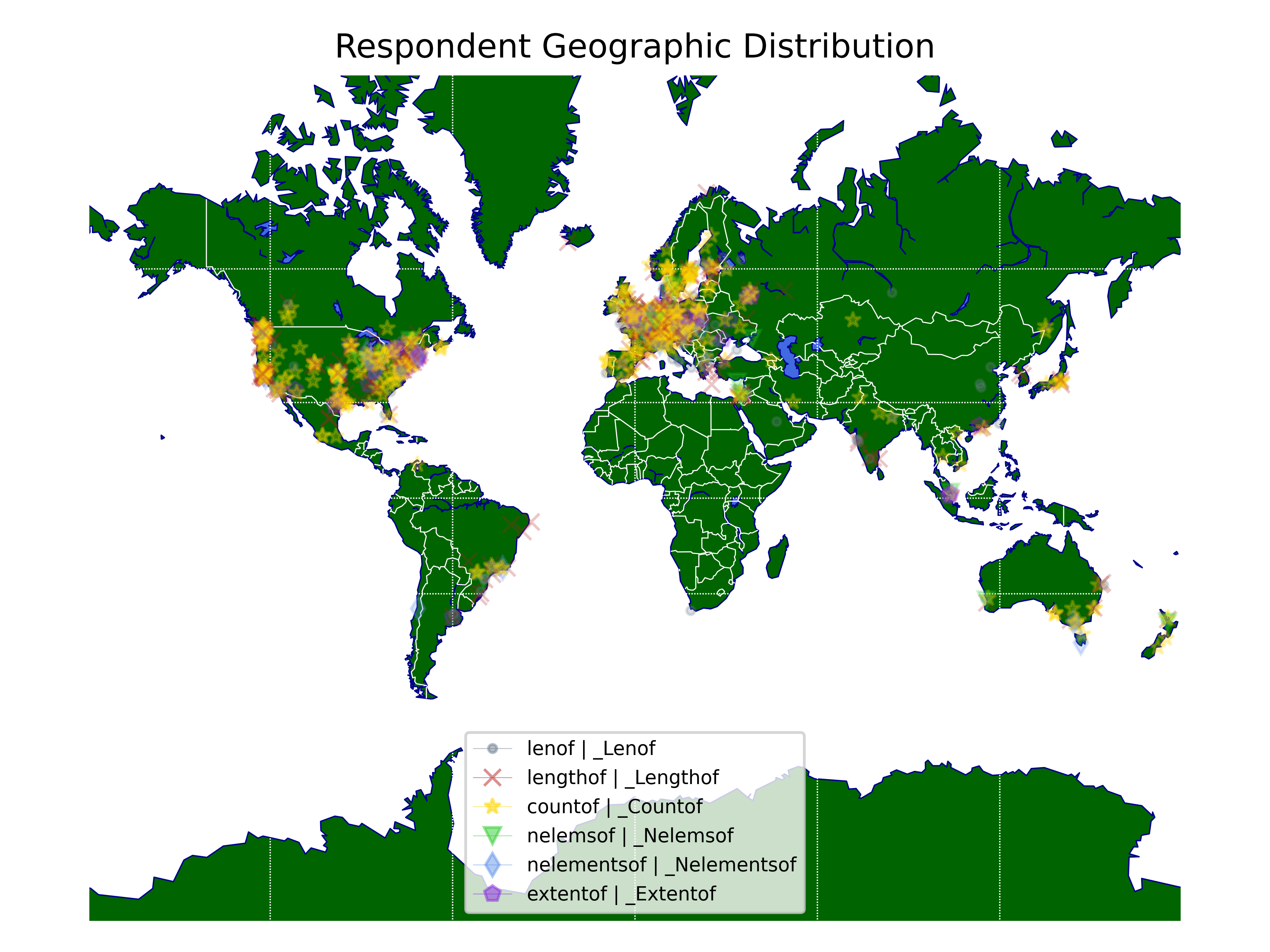
We had people from all sorts of cities participating:

The skill level and usage experience distributions were also fairly Professional-oriented, too, with some standout folks using it for 20+ or 30+ years:
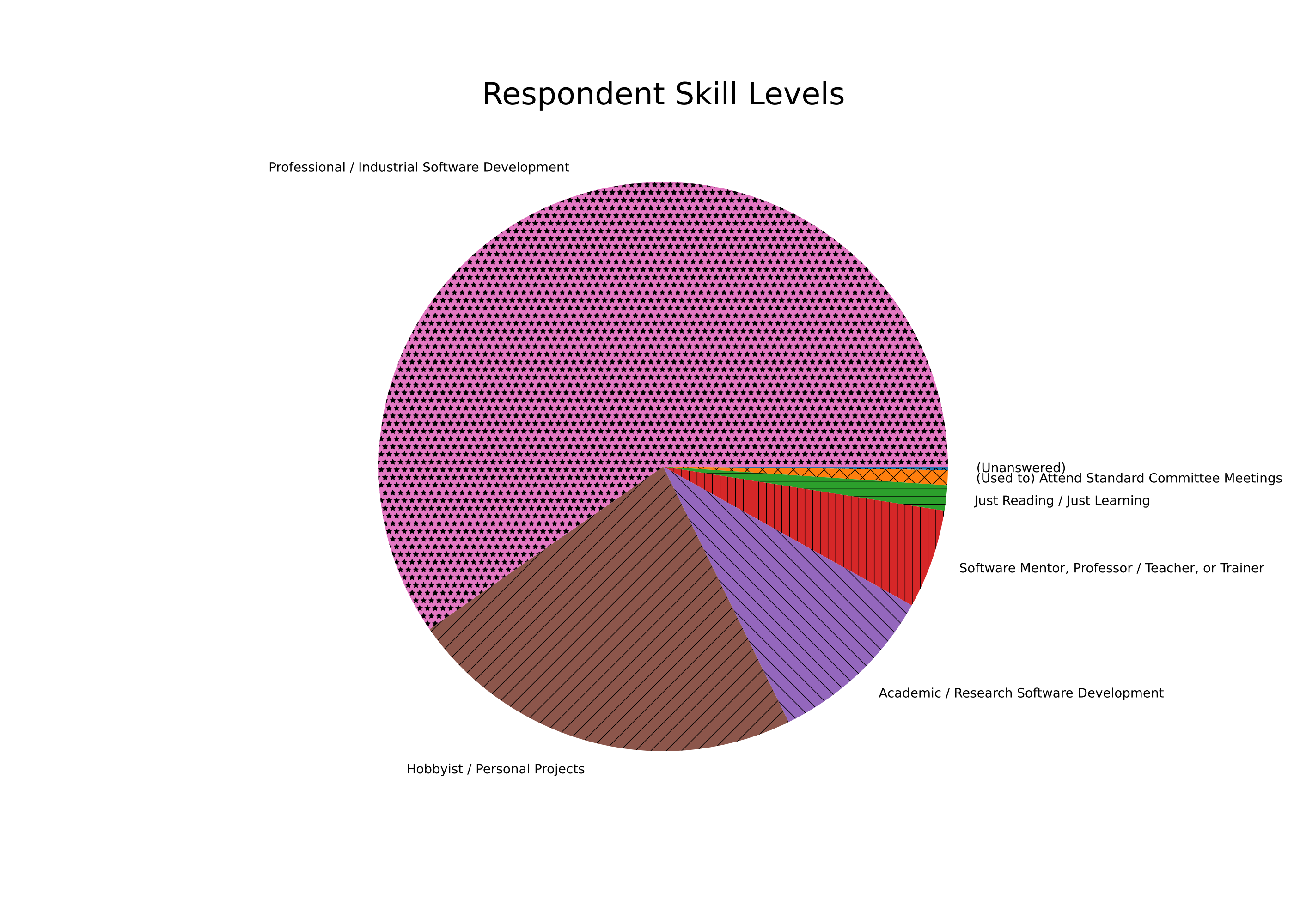
Value breakdown:
| Just Reading / Just Learning | 15 | 1.43% |
| Hobbyist / Personal Projects | 237 | 22.64% |
| Professional / Industrial Software Development | 626 | 59.68% |
| Academic / Research Software Development | 101 | 9.63% |
| Software Mentor, Professor / Teacher, or Trainer | 59 | 5.62% |
| (Used to) Attend Standard Committee Meetings | 9 | 0.86% |
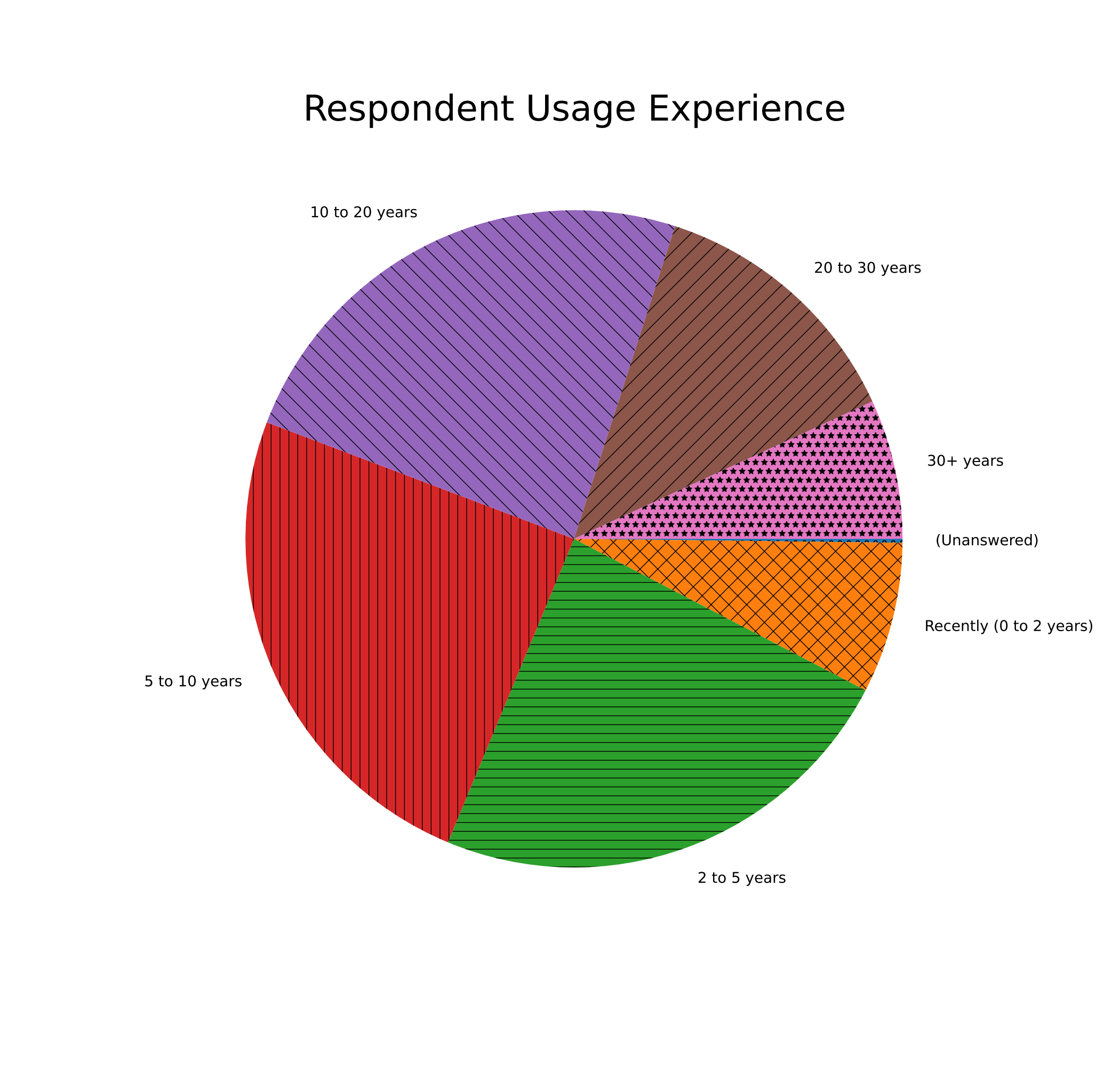
Value breakdown:
| 30+ years | 72 | 6.86% |
| 20 to 30 years | 138 | 13.16% |
| 10 to 20 years | 254 | 24.21% |
| 5 to 10 years | 257 | 24.50% |
| 2 to 5 years | 248 | 23.64% |
| Recently (0 to 2 years) | 78 | 7.44% |
I feel this is a pretty good mix of opinions to have out of a standard 1,049 person survey for a programming language, especially one as old as C! It’s pretty heartening to see folks are reading (and responding) to this website in those kinds of numbers, which is not bad considering I’m not exactly Stack Overflow over here! The overwhelming majority have also used C very, VERY recently:
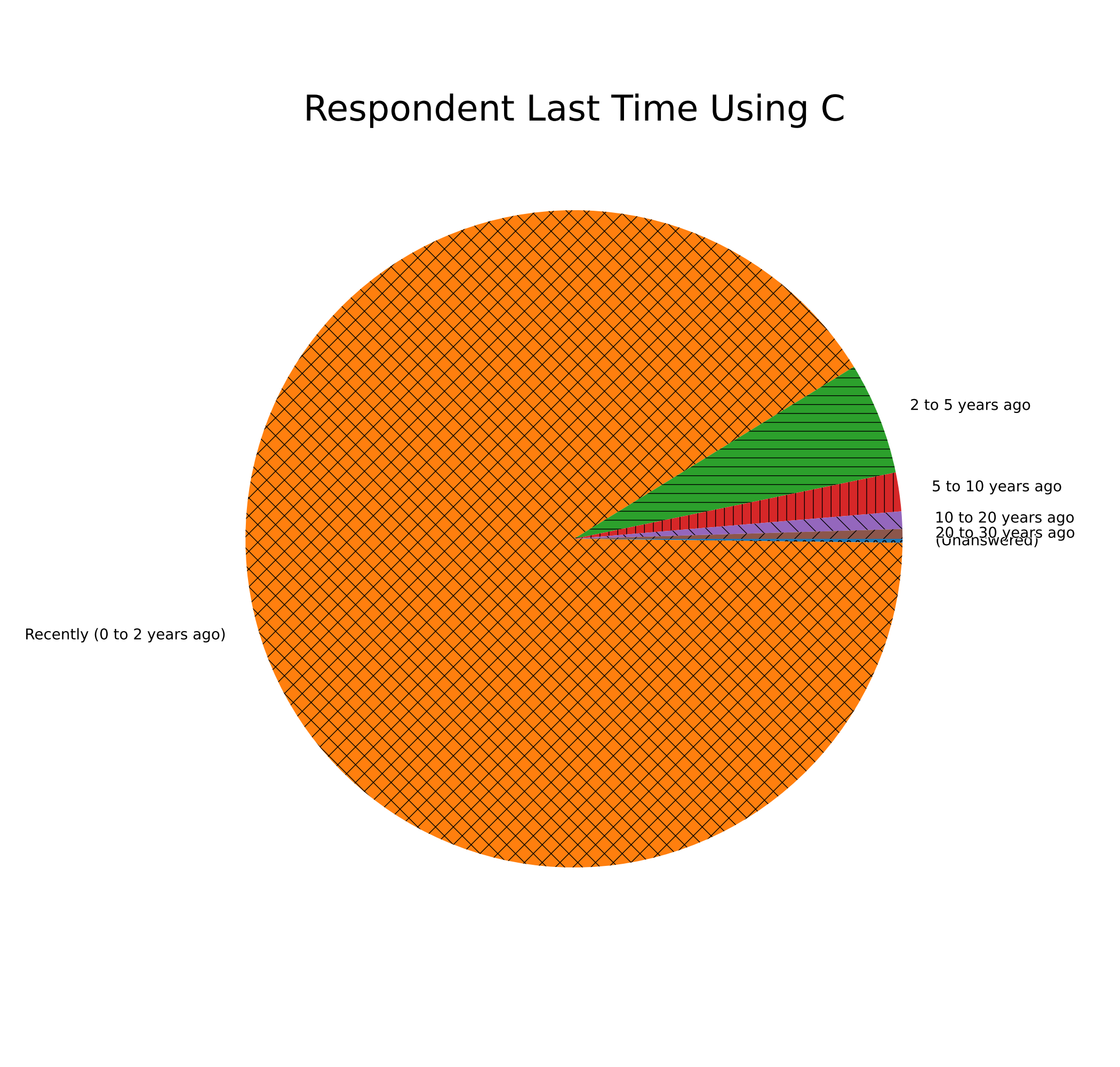
Value breakdown:
| 20 to 30 years ago | 5 | 0.48% |
| 10 to 20 years ago | 9 | 0.86% |
| 5 to 10 years ago | 20 | 1.91% |
| 2 to 5 years ago | 58 | 5.53% |
| Recently (0-2 years ago) | 955 | 91.04% |
Still, this is all just set dressing so that we can bring up the part everyone actually cares about.
The Results
Prefacing what will be an endless shitstorm of opinions and interpretations, the results are not exactly an OVERWHELMING mandate in any specific direction.
But.
There is a fairly convincing argument that there’s a few things the C community are beginning to lean towards in these recent years, exemplified in the results and the comments. Of course, this is not a unanimous lean, as the C community is huge and there’s quite a few different needs it needs to fill. But there’s a clear preference for specific options, which we’re going to start getting into below.
On the Delivery Mechanism: Keyword/Macro Style Regardless of Spelling
Here’s the results for the three options of:
- lowercase
keywordwith no header; _Keyword+stdkeyword.hmacro;- and,
_Keywordwith no header.
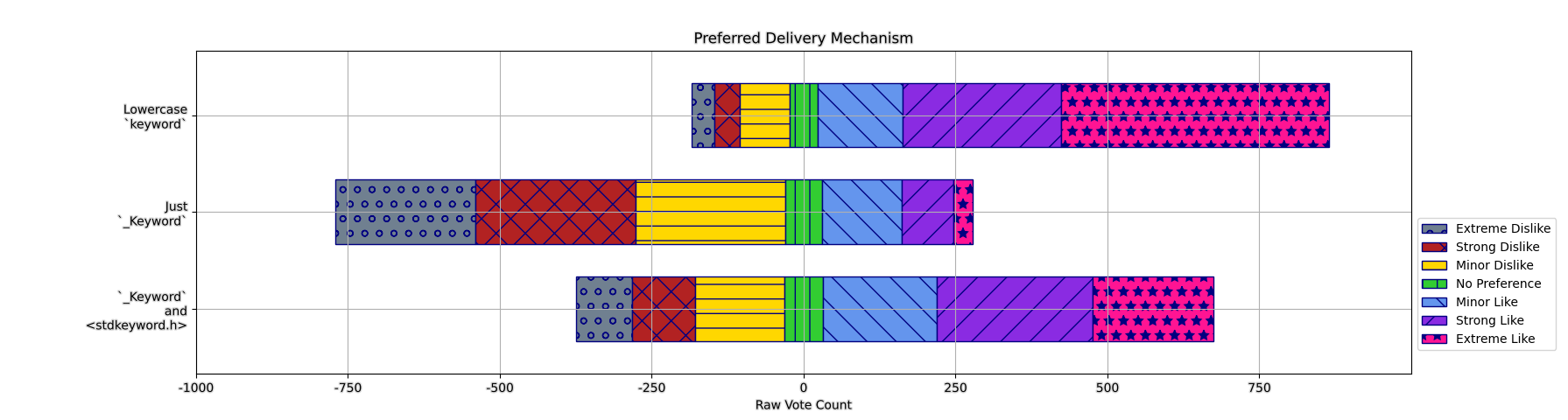
There is a clear preference for a lowercase keyword, here, though it is not by the biggest margin. One would imagine that with the way we keep standardizing things since C89 (starting with _Keyword and then adding a header with a macro) that C folks would be overwhelmingly in favor of simply continuing that style. The graph here, however, tells a different story: while there’s a large contingency that clearly hates having _Keyword by itself, it’s not the _Keyword + stdkeyword.h macro that comes out on top! It’s just having a plain lowercase keyword, instead.
One can imagine this is a far less conservative set of professionals and industry members who have begun to realize that the payoff for working with _Bool and <stdbool.h> is just not worth the struggle. Users already have to opt-in to breaking changes with standard flags. Constantly having code break because you’re not manically and persistently writing things in the ugliest way possible – and then having it breaking in some source file because you didn’t include the right things or some transitive include didn’t work – is annoying.
This doesn’t necessarily represent everyone’s ideas on the subject material, though. Some comments are strongly in-favor of the traditional spelling, for obvious reasons. From Social Media:
huh, new lowercase keyword? Have these people not heard of not breaking existing code?
This perception was immediately countered in a reply to the post:
we do and we prefer to have nice things that we can actually use.
And spend the time fixing old code
Both perspectives can also be found in the comments of the survey itself:
I think C23 is a great turning point to implement disruptive changes, so if we want a keyword (which I’m sure we want) now is the moment to introduce it. Who knows when there will be another chance of breaking away with the past like we have right now.
My 2 cents: this decision affects people twenty years from now and forward. Think about them. Make it easy for newcomers to learn C, i.e. avoid/limit arcane incantations.
I suspect if there was a header then I wouldn’t use it, but I guess it wouldn’t hurt; _Countof seems slightly easier than ‘#include
... countof(...)'. One benefit I can see to '_Countof' (etc.) over 'countof' is that it makes clear 'this is new in C2y' (so C99/etc compatible code beware), but I can also see why it standing out might not be good (since it fits in less, and C already_has_lots_of_underscores). As for the name, _Lengthof is OK but sounds a bit similar to sizeof, and I can see _Lengthof("")==1 being odd. _Nelemsof looks weird but makes a lot of sense.
Have some guts for land’s sake and just add the dang keyword!
_Keyword sucks. Officially provided functions should all be lowercase.
Header macro seems the only sane way.
In general, I’m strongly against any alteration of the global, unprefixed namespace at this point; there are enough rules as it is. Chances are whatever it is will be
#if‘d in, b/c compilers won’t support this for decades, so chances are the extra macro and header would be pointless machinery.
If an _Underscore keyword with a macro in the header is selected, I would imagine that it could transition to a lowercase-no-underscore keyword after a transition period (compare bool, alignof, etc.)
This, of course, is in opposition to other comments made:
While I hate the transition period between underscores macros and lowercase keywords, I recognize it is necessary for such a basic and core concept that will have been implemented independently many times over the last 40+ years. Opting in with a header feels too obtuse however.
why not just a macro in a header? strong dislike for a keyword. especially since the operator already conflicts with names I am aware of.
And, as normal, _Generic-style underscore keywords only are the least popular idea ever:
using _Under naming and not including a macro in a header would be frustrating
Interestingly, there was an idea to have an explicit in-source way of opting into the new spelling. Because there’s no such controls in the C language at this time, it manifested in the usual request for improvements to C being cordoned off into a new header entirely:
I would like macro headers (like stdbool.h, stdalign.h, assert.h (I think?)) if we could get all of the ones relevant to a given version of C under one single umbrella header, like stdc23.h or similar
(The “I think?” here is correct - until C23 static_assert was actually spelled _Static_assert instead.) I think the desire to be able to opt into a specific standards version are usually something left to command line flags, but I will say that such command line flags – as they generally come from outside the source and from a build system (or a… ““build system””) – are annoying to library developers. Getting clean builds across multiple compilers is often an exercise in futility, especially if you abandon the open source world and start doing proprietary work (MSVC, ${Embedded and Accelerator Devs here}, …). A header seems like the best “what we do with current technology” bit right now, but others have ideas to make dialects more recognizable through source code like N3407.
My personal opinion is that the opposition to the traditional method may honestly be a pragmatic long-term choice. Introducing a _Keyword, waiting 12 to 30 years, and then just making it a lowercase version anyways as the roar of “it’s very stupid that I have to write things the ass-backwards way unless I include a header” grows louder is a song and dance a lot of people have not been happy to do over time. This flies in the face of “old code should port to new versions of the standard fairly simply”, however, so of course the usual conservative concerns are likely to prevail overall in Committee discussion when this survey is brought up.
The point that C23 – and perhaps C2y – may be disruptive enough to justify just adding the keywords directly is a tempting idea, though. And I’m certainly not one to really enjoy the underscore-keyword + header two-step we’ve developed in C. But, if we were doing raw democracy, the lowercase keyword folks would prevail here.
On the Spelling: Which Word To Use Regardless of Delivery
There was a clear preference among the results out of the following choices:
extentof/_Extentofnelementsof/_Nelementsof;nelemsof/_Nelemsof;countof/_Countof;lengthof/_Lengthof;- and,
lenofof/_Lenof.
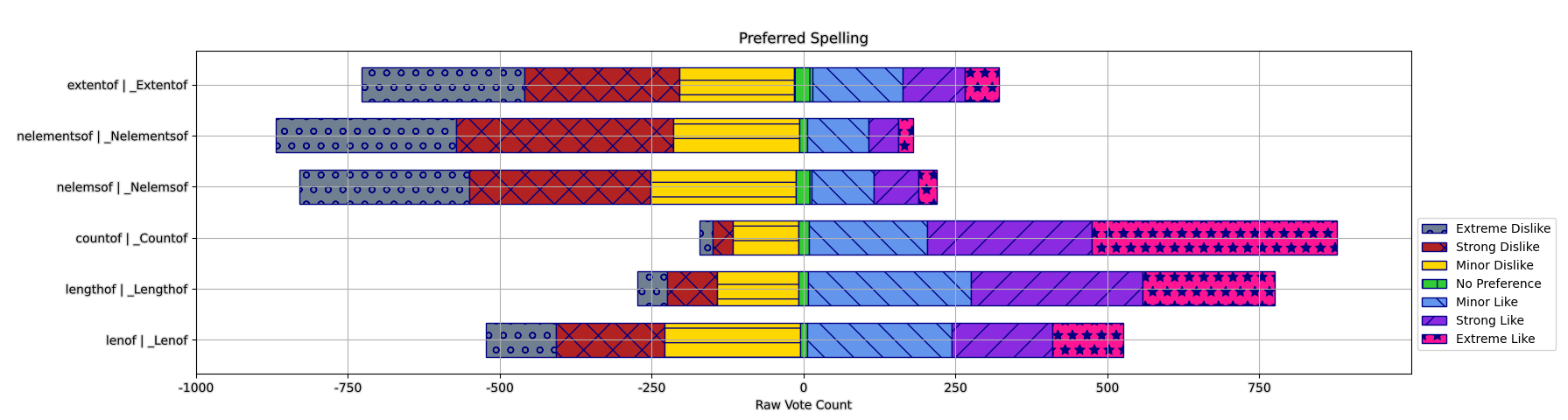
This one is actually more interesting after perusing the comments and seeing what people wrote on social media and in forums in reponse to this. There is actually a small degree of backlash against _Lengthof/lengthof due to its associations with strings, and the problem of length and strlen implying a count of N-1 (or up to the null terminator) when the operator doesn’t behave like that at all. In fact:
The off-by-ones are real with string literals. When we banned span construction from string literals in Chromium we found code expecting to make a span without the nul but it was including it of course. We have two explicit ways to make a span from a string literals that make the user choose to include nul or not (the default, which matches what you see in the code).
This sentiment was repeated in the comments of the survey:
I think countof is the best option because it’s less likely than lengthof/lemon to get confused with string length, much easier to remember how to spell than nelements/nelems/etc. (especially for non-English speakers), and extremely clear in its meaning.
I’d like different terminologies for different things. Let “length” be for “string length”, “size” be for “in-memory size (in bytes)”, so “count” is for “element count”.
Some people had less technical reasons for hating any given option, though. Some of it boiled down to raw preference, or just simply being reminded of things they disliked:
Count reminds me of PHP, which is why I hate. The most appealing option is having beginners learn that the size of something is often in bytes while the length of something is in blocks of arbitrary size. Something simple that’s not hard to remember or to write.
And others clung to the strict mathematics / old-person’s like of “extent”:
Neither count, size or length do well with multidimensional arrays. One might justifiably expect
countof((int[4][4]){})orlengthof((int[4][4]){})to be 16 instead of 4. So while I like countof more, I think extentof is the most unambiguous naming.
But, ultimately, the stacked bar chart shows that not only is countof and _Countof the most liked, it’s also the least disliked. It’s better on just about every metric insofar as the counted votes are concerned, really. This isn’t the say that it would have always been on top, given different spellings. There were a lot of protesting comments, wanting either more options or completely different options entirely:
nelems() would be better than nelemsof(), to be consistent with nitems().
Please consider “arraysizeof” or “asizeof” or “arraysize”
Why not refer to prior arts? What are these options??
_Array_size
arraycount()
Just use nitems. What existing definition” is there to clobber that isn’t already exactly what you’re trying to achieve? Why do we need to invent yet another name? All the suggestions are trying to contort themselves around not being nitems. “of” suffix is not important to chase.
I’d rather that you standardized existing practice unchanged; the BSD macros are fine. But if you must standardize an operator, at least let me pretend it doesn’t exist. I won’t use it, because there’s only portability-related downside over the macro based version.
I don’t see how ARRAY_SIZE would be awkward, it’s what I have in my own code
My macro is C_ARRAY_SIZE(a)
arrsizeof- 42 files on github
I feel like nof or noof should’ve been an option
There’s a lot of ask for arraycount/arraysize that showed up, but the reason those were culled from the running early (just like nitems) is simply because the blast radius was known to be enormous; any spelling of that was going to blow up a million people. This was even worse for comments that suggested we take the of off of lenof or lengthof or countof to just be count, len, or length; the number of identifiers people would need to goosestep around would be enormous. nelementsof was the original plan from the paper before the ARM Survey conducted by Bazley swayed Committee opinion. I, personally, expected lengthof/_Lengthof to win in this wider survey I conducted; I expected ARM’s engineering consensus to be the dominant consensus throughout the industry.
But, that seems not to be the case!
On the Exact Spelling: A Cross-Section of Delivery and Spelling
There’s not too much to say about this: it’s got a lot less responses since it was an optional question (~650 filled out, versus the 1040+ for the other mandatory questions). But, even with a reduced pool, the same trends and ideas from combining the other two polls manifest fairly reliably for the exact spelling options:
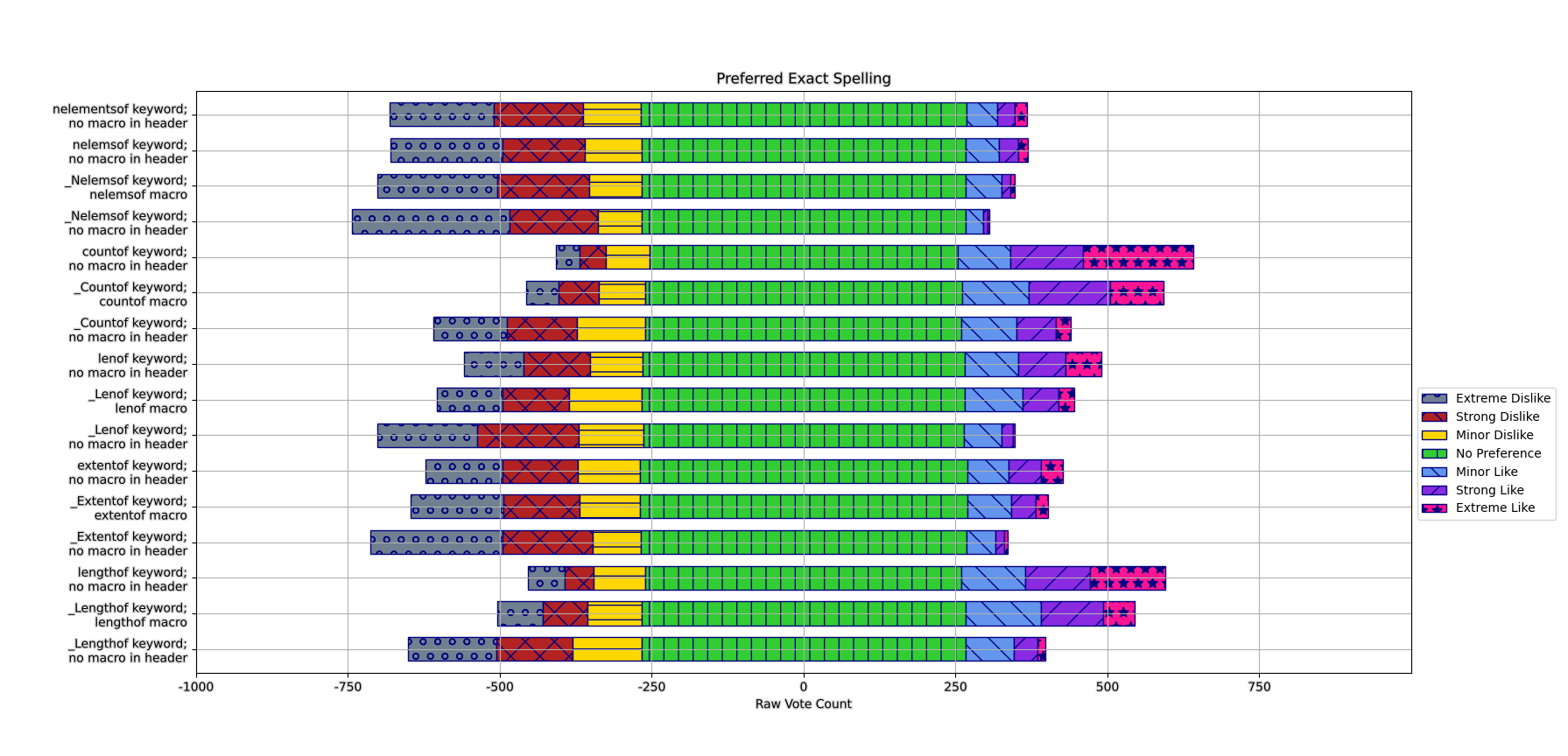
Namely, countof as a keyword with no macro or header has the least dislike and the most likes. Various options steadily fall off from there. In the specific options, lengthof as a keyword with no macro or header comes close, and then from there it’s lengthof/countof as macros in a header, and then various worse options as one continues to look for different combinations. It more or less reinforces the previously points. There’s more comments (some funny/irrelevant ones too), but I think this should provide a solid basis for the necessary data.
I expect people to simply keep bikeshedding. Even with all of this data people will still argue for and against things, but at least I can say I did get the data for all of this! 💚
- Banner and Title Photo by Mikael Blomkvist, from Pexels: https://www.pexels.com/photo/person-using-white-ipad-6476590/