The warm up is done, and it is time to choose. Not between Apples and Pears (would pick apples, by the way). It’s time to make some choices about something that’s been looming over the Standards Committee for a long time, and is part of two pretty important papers in the San Diego mailing: optional.
Now, before some of you sharpen your rebind spears and assign-through broadswords and brandish them in my direction: this will not talk about rebind and assign-through. Because, at the end of the day, those choices are irrelevant to the 2 proposals on the table that need to be discussed: p0798 - Monadic operations for std::optional and p1175 - a simple, practical optional reference for C++.
First, however, a bit of history. You can skip down to “The Practicality of References” if you are not interested in the backstory bits.
History
One of the Nine Circles of Committee Hell, std::optional and its treatment of references – alongside std::variant, std::expected and other vocabulary types – have long plagued original boost::optional author Fernando Cacciola with its standardization process. References in vocabulary types are the subject of a whopping multi-hundred e-mail chains in the Boost mailing list, several blog posts, over 20 collective revised papers from a time before I even knew C++ was a thing (back in the days when proposals were N-numbered), and a whole lot more. Most recent among them is a blog post from Jonathan Boccara. This essentially recaps the holy war (just peek in the comments and on the reddit thread for it), and neither side is yielding anything to the other in terms of how references should be handled.
Meanwhile – in industry and the real world outside of bikeshed land – people are making lots of workarounds and choices about their optionals. Some companies that have access to boost continue to use boost::optional. Some port entirely to using T* for their optional references after giving up on boost (though it is notably painful for many developers and codebases). Others still roll their own optionals: particularly, Simon Brand rolled tl::optional, Andrzej Krzemieński rolled std::experimental::optional, I rolled a version derived from Andrzej’s in sol2 with some exception-less and constexpr changes, Jonathan Müller rolled ts::optional_ref, and many others have their own Maybe variants and other internal optionals. And while this is good and fine for their individual codebases, a bigger problem emerges.
The Ecosystem is Fragmented
Whose optional do you use? The ones above aren’t the only ones: there are at least 5 more public implementations, from Martin Moene’s to Isabelle Muerte’s. All of them have tiny little quirks, and all of them are by-name different types, despite trying to implement the exact same type. This means that a function taking one optional from one codebase essentially tells everyone else’s optional – including the C++17 standard one – to get lost. This is a serious problem: before, there was either some company-internal type, or boost. Code was not shared that much. Libraries were not shared that much, especially not ones making use of these idioms too often.
In the age of GitHub and Bitbucket and lots of sharing, there is little value in having 20 implementations of a common vocabulary type. Having multiple incompatible optional implementations throws portability and reasoning out the window, and yet to this day people are still working with and using non-standard optionals despite having a C++17 compiler and standard library available.
What’s the deal?
Searching for Truth
A while ago, in preparation for a huge paper that would take a side on the holy war talked about in Jonathan Boccara’s post, I made a survey about optional. I sent out over a dozen e-mails before then, and then a good eight more after it. I (accidentally) ran headlong into legal teams wondering why I was asking their employees about their code, I plunged into the history of several different optional types both pre-dating and post-dating boost::optional, and I even e-mailed authors of the first reference wrapper types for C++ (that go back as far as pre-2000)! It was an enlightening experience, absolutely, and messaging and reaching out to Douglas McGregor and Jaakko Järvi (original boost::tuple author) made the journey incredibly fascinating.
But that deep-dive is for a later date.
We are not going to talk about rebinding or assign-through or consistency or any of that. There is a much bigger topic that quite firmly supersedes all of these notions.
The Practicality of References (Benching p0798)
References are immensely practical and bring real performance gains to applications. But how much gain do they bring to the table? For this, we take Simon Brand’s p0798 - Monadic operations for std::optional and ask a very simple question:
What is the performance of shoving some basic data types through the monadic operations a handful of times, with and without references?
Important to note: p0798 introduces the feature that was the #1 feature request in the C++ Developer Optional Survey I ran. Monadic operations such as map/and_then/etc. outranked even the want for references in optionals (by a handful of votes).
In either case, the investigation of performance was sparked by some comments in a conversation I was having about piping things through p0798’s optionals multiple times and noticing performance was not equivalent to in-place operations:
It tends to be helped by copy elision quite a bit, but otherwise that’s probably fair. Compilers are good with values generally. Since they’re easier to reason about.
So, well. How good are compilers, really?
Testing the Theory
As mentioned in the history, Simon Brand has implemented an exceedingly high-quality tl::optional which is used as part of the fodder in his excellent CppCon 2018 talk, How to Write Well-Behaved Value Wrappers:
I was in the audience for this one and the volunteer helping out with it, but that will come during a (very late, I’m working on it…) Trip Report to CppCon 2018.
The point being made here is that Simon’s code is some Q U A L I T Y C R I S P work and much effort has gone into it to preserve all the necessary properties of types and be as well-behaved and fast as possible (which is essentially what I would expect from a Standard Library implementation). It also supports references, which means we have a fair base for which we can compare propagating values or references through map and and_then operations. Here’s the idea of what we are benchmarking:
tl::optional<std::vector<int>> maybe_value = /* { ... } */;
tl::optional<std::vector<int>> post_maybe_value = maybe_value.map(transform)
.map(transform)
.map(transform);
The full code, buildable with CMake and runnable with a pretty graph-visualizer, is all set in this repository. There are a few things we test here. First, we test the basic case: cheap values that can fit in registers (integers, basically). We then have tests for another common type: std::vector<int>. We do not put anything special in the vector except integers, because that enables the memcpy optimizations where possible. As another layer, we compare doing only 1 monadic operation, compared to piping through 3 operations. Finally, for both of these, we test when the code is completely visible to the compiler (marked with _transparent in the name). This means it is available for inlining. We then also test the case where the code is completely invisible / opaque to the compiler. Anything without _transparent had its transform function call hidden behind a DLL call. This was to test if inlining was the defining performance gain factor or not.
As a slight addendum and a fail-safe to test if the code went wrong, there are also two sections: one is marked _failure, and this just means that the optional was empty so no work should have been done in the monadic functions. It’s essentially a basic litmus test for “is something haywire happening in the benchmarks right now?”. There is also _success, where the optional was filled with a value and everything worked out.
As part of the benchmark, computed values are checked for legitimacy, to make sure the optimizer doesn’t just toss everything out on us. Our transformation is essentially just multiplying every element in the vector by 2, then returning the result.
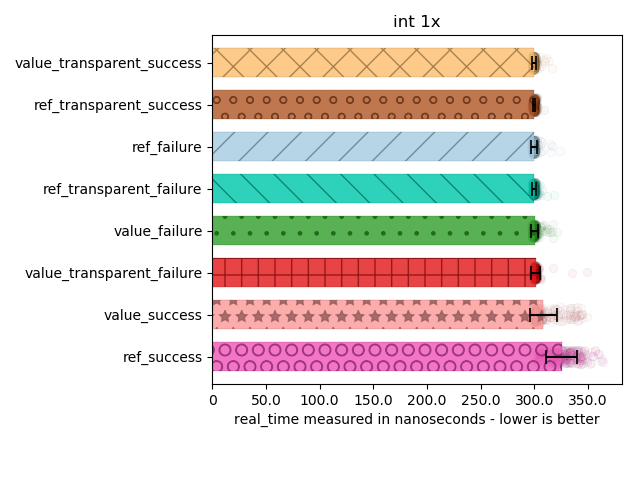
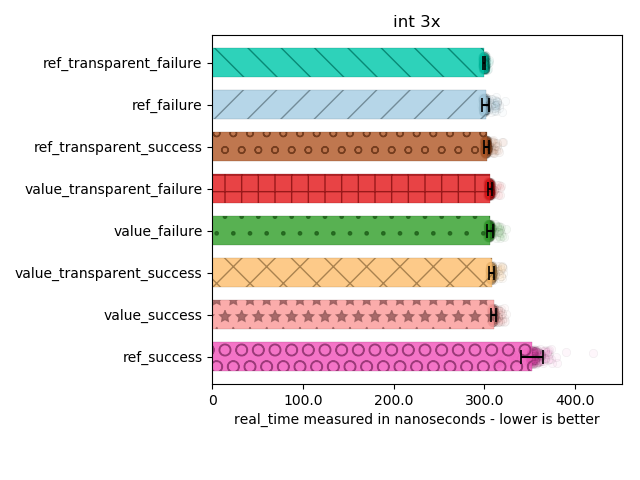
For int
No surprises here: int is dirt cheap, so references don’t buy us anything at all in terms of speed:
For std::vector
Now, things get spicy:
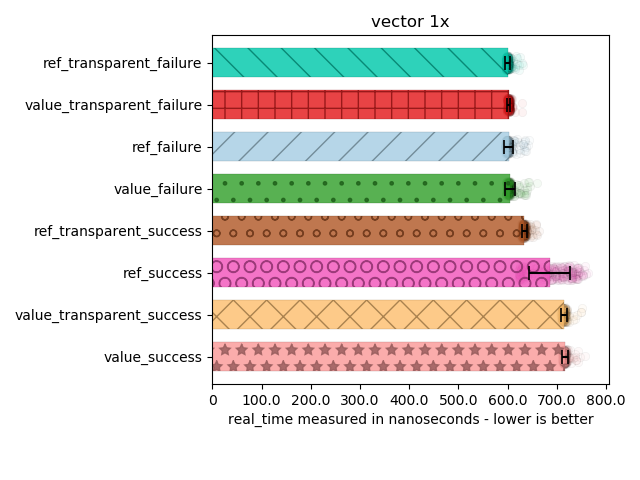
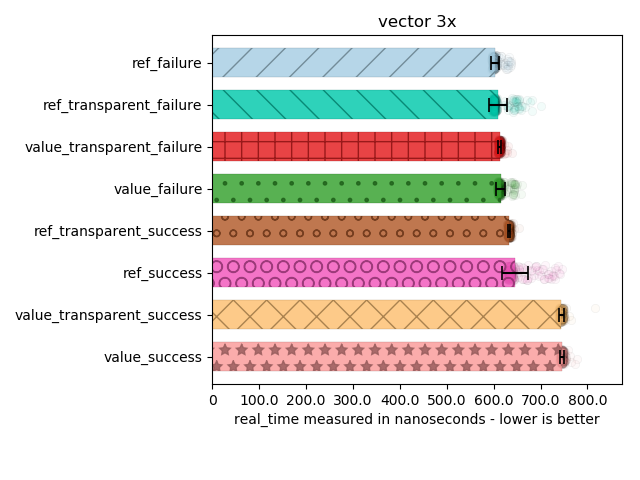
In all cases, values perform worse. However, something weird seemed to happened with the spread of a DLL-barriered call to transform: it’s all over the place! The standard deviations are huge on these calls in particular. Everything else makes it very clear that values do not win when you have non-trivial types going into your monadic operations. The compiler can’t just elide all the copies/moves entirely. We also see that inlining can provide some performance gain, but not all of it: both DLL-hidden and non-DLL-hidden transformations perform better with references.
Wait a second, it’s only nanoseconds…!
Right. These benchmarks already take an age to run (literally hours) because of the serious confidence that needs to be established by Google Benchmark, so it runs anywhere from ten thousand times to 4 million times. Therefore, to not have to die of old age waiting for the statistics to compute the 4 million iterations for each and every sample, the vectors only had 8 ints in them. I’m sure if you put MyBigHonkinExpensiveType in the vector, these numbers would get DRAMATICALLY worse. But I don’t have the laptop to fry over running that benchmark! ♩~
As we can see, there is clearly a measurable benefit to references. Which is part of the reason why financial companies, LLVM shops, and other places are still using tl::optional or inventing their own type with reference and void specializations. Matt Calabrese’s Regular Void paper will one day fix void specializations so that everything is okay. But, the references question is still an open one. Given the performance benefits, the fact that it is frustrating to suffer random copies in the middle of generic code because std::optional will throw a hissy fit, and because sometimes it is not okay to go back and change all prior code using references to return std::reference_wrappers, Simon Brand’s paper needs a partner paper! A partner like…
p1175 - a simple and practical optional for C++
This paper removes anything and everything that could spark the holy war and presents an optional that not only adds references, but is designed to cover the 80% use cases where optional is found today. This is for: function arguments, return types, and keeping programmer intent. For any type-based binding layers (e.g., bindings that use type declarations), it not only helps programmers express their intent more correctly but enables additional performance by separating the null state from the potential values of the desired type (this has performance implications for how certain binding layers such as sol2 can retrieve values from the underlying system).
The good news is that this paper lets the C++ Committee continue to wage the holy war about how comparison and assignment for such a type should work while providing a way forward for not only std::optional<T&>, but variant<T&, ...> and std::expected<T&>. When such a time as the dust settles on how people want to handle these types, it can be added to C++ with no breakage to users. The immense benefit is that we can have users stop implementing their own optional.
It also makes sure that the Monadic Operations that get standardized and the example in p0798’s paper remains copy-less and quick:
std::optional<image> get_cute_cat (const image& img) {
return crop_to_cat(img) // creates new image
.and_then(add_bow_tie) // no need to copy
.and_then(make_eyes_sparkle) // no need to copy
.map(make_smaller) // new, smaller image
.map(add_rainbow); // no copy
}
Rather than having 3-4 additional copies.
For both p1175 and p0798, Strongly in Favor!
But what about T*?
Pointers are a non-starter for optional references in the case of function arguments in particular. However, this post is already fairly long: if you want to be baptized in the waters of good type design with pointers, watch Jonathan Müller’s C++Now 2018 Rethinking Pointers talk.
And That’s All!
Another 2 papers down. Do you have any recommendations for any papers I should seriously look into? The others I wanted to take a look at were [[constinit]] by Eric W. F. and [[shared]] from Isabella Muerte. There’s also an interesting new Cooperatively Interruptible Joining Thread type. Tweet at me or e-mail me if you have any suggestions!
Toodle-oo. ♥