Delicious cheese rests on the other side of that fence, enticing mice like myself and my users! It’s a very dangerous trap. Almost as dangerous, in fact, as the One Definition Rule.
One Definition Rule (ODR) is a hallmark of C++, which allows its Parameterized Nondeterministic Abstract Machine to properly handle the separated declaration/definition, includes-based copy-paste library usage, inline methods, and template programming plus its various consequences without bringing everything down in one big flame. I recently gained some serious performance in sol3, but in doing so left an enormous trap for my users thanks to how ODR works. We’re going to talk about what the problem is and ultimately what solution I am going to be choosing for sol3.
Rules, and Power
It is critical to note that even for such an important tenet, the One Definition Rule is exactly that: a rule. Most other things that go wrong in C++’s abstract machine are classified with a Phrase of Power called “ill-formed”. This means that the abstract machine has to stop and tell you that something is wrong with your program, and terminate the program (in the case of most compilers today, that means stop compilation. But if you were running C++ through, say, an interpreter, then that means stop execution). This makes them less rules, and more Steel-clad Law. The One Definition Rule is funny in that in some cases, the compiler is not required to terminate: this is another Phrase of Power, called “Ill-formed, (with) No Diagnostic Required” (ill-formed (w/) NDR).
What does it mean to for an ill-formed NDR to happen in your program?
It means your program might compile. And it might run. Most things classified by ill-formed NDR means the compiler can do a best-effort attempt to kick the compilation in its face and stop it from going any further. But it can do anything under the sun at that point, because it is an ill-formed program that violates the tenets of the abstract machine. The only holding corollary is that once you violate a fundamental tenet like this, your entire program’s working state is now up in the air: you are now in the world of Undefined Behavior. Let’s illustrate with a poignant example:
func.h++
#pragma once
int func ();
func1.c++
#include <func.h++>
int func () {
return 1;
}
func2.c++
#include <func.h++>
int func () {
return 2;
}
main.c++
#include <func.h++>
int main (int, char*[]) {
return func();
}
Most compilers say you’ve done a bad thing, and yank on that little mousey tail before you skitter off into the trap:
> func1.c++
> func2.c++
> main.c++
> Generating Code...
> func2.obj : error LNK2005: "int __cdecl func(void)" (?func@@YAHXZ)
already defined in func1.obj
> Project\x86\Debug\Project.exe : fatal error LNK1169: one or more
multiply defined symbols found
Good, good. Even though there’s no diagnostic required, we at least get a Linker Error. Which isn’t exactly the best of all kinds of errors, but at least the build stops.
Spicing it Up
Now let’s throw on some Sriracha (or perhaps you’re a Tabasco person?). What happens when the mistake is caused by something a lot more sinister? The above is caught by the linker because it is the linker’s job to fold multiple symbols defined in different translation units down into one definition. When that is ambiguous for the rules compilers use (mangled name + similar arguments), it gives you a (mangled) error. But what about constructs like an inline function and a macro? Observe:
inline_func.h++
#pragma once
inline int inline_func () {
#ifdef CONFIG_STUFF
return 1;
#else
return 2;
#endif
}
use.h++
#pragma once
int use_1 ();
int use_2 ();
use_1.c++
#include <inline_func.h++>
int use_1 () {
return inline_func();
}
use_2.c++
#define CONFIG_STUFF 1
#include <inline_func.h++>
int use_2 () {
return inline_func();
}
main.c++
#include <use.h++>
int main () {
return use_1() + use_2();
}
We have 2 uses of inline_func. One is supposed to return 1, the other is supposed to return 2. But it’s an inline definition, and as per the One Definition Rule, there is only supposed to be one definition. Having 2 definitions 2 with different implementations is assuredly a violation of the rule. And the compiler can see that the code inside is fundamentally different, right? The compiler can save us from triggering this and having our poor bodies clamped in the vice-grip of the mouse trap-
> use_1.c++
> use_2.c++
> main.c++
> Generating Code...
> Project.vcxproj -> Project\x86\Debug\Project.exe
========== Build All: 1 succeeded, 0 failed, 0 skipped ==========
… Well, damn. Now we’re in the red here. Which definition did the linker pick? One? Both? None? The compiler won’t warn you about your failure here. Does the program even ru-
The program ‘[25244] Project.exe’ has exited with code 2 (0x2).
… Okay, so it runs too. It picked the definition with the #define on, returned 1, and then added both together to return that value. Maybe? It’s ill-formed, but there’s no diagnostic. The implementation just makes some choice because we passed the compiler’s heuristics for determining if we followed the One Definition Rule, because all of our definitions are supposed to be identical for an inline function (class methods defined in the class are also implicitly declared inline as well).
Why didn’t the compiler save us from our mistake? This is clearly a bad idea: the implementations were different! Couldn’t the compiler just check all the code and make sure it is identical? And it could. But, consider the not-so-infrequent use of something like <vector>. As a template class, 99% of its definition needs to be in the header, inside of a template. It’s all inline, as far as the world is concerned. So for every translation unit that features <vector>, the compiler would need to do exhaustive checks for every single definition of every class and function to make sure they are identical after compilation, and issue and error if its not. And for <string>. And for <iostream>. And for-
Yeah, okay, that’s not feasible.
This is why it is ill-formed, NDR. This Phrase of Power is for the things the Standard knows are wrong, but it would essentially be extremely prohibitive and/or exceedingly crazy to require the implementation to diagnose. Compile times would be measured in weeks, not hours, and #include-based programming would die on the spot (or vendors just wouldn’t diagnose it, and there would be a de-jure vs. de-facto split that would not do anyone any good).
Well, Come On! Who Writes Code Like That?
Everyone, actually. Everyone likes to talk about how terrible macros are, but everyone uses them. Whether you want it or not, if you Follow the River, You Will Find the C. You may not like macros but they are the go-to way to customize C and C++ code. Every prominent C library from zlib to freetype gives you a config.h to cram defines in to change library behavior, and you had better make sure it’s exactly the same when you are both building the library and using the library (unless the documentation provides explicit sanctuary otherwise).
Even if you don’t pick up these sorts of libraries, standard libraries have debug defines for iterator checking. Compilers define macros for their versions. They’re everywhere, and it’s impossible to avoid this problem. “Macros are a mistake”, I hear you groaning. But it’s alright, macros aren’t the only monster here: beautiful, modern C++ loads that shotgun and aims it right for your big toe:
fooable.h++
#include <type_traits>
template <typename T>
struct is_fooable : std::false_type {};
template <typename T>
constexpr bool is_fooable_v = is_fooable<T>::value;
do_something.h++
#include <fooable.h++>
template <typename T>
inline void do_something() {
if constexpr(is_fooable_v<T>) {
// do one thing
}
else {
// do another thing
}
}
blah.h++
struct blah {
void foo ();
};
use_1.c++
#include <fooable.h++>
#include <do_something.h++>
#include <blah.h++>
template <>
struct is_fooable<blah> : std::true_type {};
void compute_1 () {
do_something<blah>();
}
use_2.c++
#include <fooable.h++>
#include <do_something.h++>
#include <blah.h++>
// there's no specialization!!
void compute_2 () {
do_something<blah>();
}
The template specialization is visible in one translation unit, but not in the other. But, the program is going to fold do_something<blah> into one definition, as per the One Definition Rule. This is also not-diagnosed by compilers.
Okay, but why are you telling me all this?
These are very important examples because in sol3 I introduced macros that did exactly this, and got a very critical performance boost:
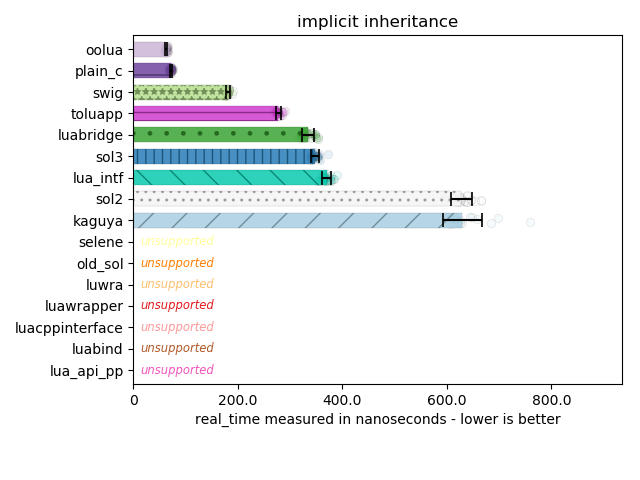
But in doing so set this ODR trap for my users. A long time ago when sol2 was still getting off its feet, I got into a discussion about whether or not safety was required for sol2. My opinion was that it should be something you can turn on (and should be on by default in debug builds), but when someone kicked on optimizations all of it should go away and we should trust the programmer and treat them as a Very Smart Person:
I think it depends. For constant development, you want the safeties on (perhaps by default during debug builds). But, for release code, you generally want to take all of the safeties off once you’ve thoroughly used / tested the code, even for a dynamic language. - July 11th, 2016
Users who forget to make it available everywhere they use sol3’s code to work with the class targeted by those template specializations will suffer crippling and hard-to-track ODR bugs. On the other hand, that’s some nice speed. Is the trade-off worth it…? Or, put more succinctly and pointedly:
Can I trust you?
This boils down to a problem of both discipline and trust. As a library author, that speed increase is compelling. But if it creates too much of a footgun, I either need a new design or something to replace it entirely. If I do leave in such a footgun, is it possible for me to trust my userbase to use it without hurting themselves and their products?
Reflection (constexpr-style Reflection, which is what is being pursued by the committee now) would allow me to just work with the type itself directly and not have to do these crazy things. But! Reflection is not coming until C++23 or C++26. We might get a TS implemented in C++20, but there’s no guarantee even the Big 4 Compilers (MSVC, EDG, Clang and GCC) will implement the TS.
If the choice was between this or the old method, I would probably choose the old method and leave the template specialization method out, speed or no. ODR bugs are a pain and hard to handle… but! Instead for sol3, I have developed a hybrid system. For every type you register into the system, you can use what was done in sol2 and specify a list of bases manually with sol::bases<Base1, SuperBase1, SuperBase2, ...>. This does not rely on the same template tricks and doesn’t cause the same ODR issues.
You can selectively opt into the more-performant code by using the template specialization. Particularly, by sprinkling SOL_BASE_CLASSES(MyType, Base1, SuperBase1, SuperBase2, ...) and SOL_DERIVED_CLASSES(Base1, MyType) + SOL_DERIVED_CLASSES(SuperBase1, MyType) + etc… . It will override the base code, which means you can have both. This lets people use the safe runtime version that does not require you to put the markup in every translation unit you need, but opt-into the compile-time, constexpr bool version that provides so much of the performance. It also makes it so even if the ODR-violation folds into the wrong version, it won’t just be segfault-levels of wrong – it will just be slower.
To make it so people do not have to include all of sol3 in order to get these benefits, I also have a sol/forward.hpp header that has these specialization-ready templates and macros. This will reduce friction with individuals who do not want to include all of sol3 just to define the specializations for speed in their own header files to reduce the chance of making the mistakes above (if the template specialization is right next to the class, it is impossible to forget!).
When Reflection finally comes to C++, I’ll be able to deprecate both. But, I leave these template specializations – and these macros – in because ultimately? You’re a good mouse, and an even smarter developer. You are thoughtful and careful and will not trigger the trap.
I trust you. You’ll get the 🧀!
See you later. 💛